-- \i tmp.sql
CREATE TABLE graph(
account_id integer NOT NULL --references accounts(id)
, device_id integer not NULL --references(devices(id)
,PRIMARY KEY(account_id, device_id)
);
INSERT INTO graph (account_id, device_id)VALUES
(1,10) ,(1,11) ,(1,12)
,(2,10)
,(3,11) ,(3,13) ,(3,14)
,(4,15)
,(5,15)
,(6,16)
;
-- SELECT* FROM graph ;
-- Find the (3) group leaders
WITH seed AS (
SELECT row_number() OVER () AS cluster_id -- give them a number
, g.account_id
, g.device_id
FROM graph g
WHERE NOT EXISTS (SELECT*
FROM graph nx
WHERE (nx.account_id = g.account_id OR nx.device_id = g.device_id)
AND nx.ctid < g.ctid
)
)
-- SELECT * FROM seed;
;
WITH recursive omg AS (
--use the above CTE in a sub-CTE
WITH seed AS (
SELECT row_number()OVER () AS cluster_id
, g.account_id
, g.device_id
, g.ctid AS wtf --we need an (ordered!) canonical id for the tuples
-- ,just to identify and exclude them
FROM graph g
WHERE NOT EXISTS (SELECT*
FROM graph nx
WHERE (nx.account_id = g.account_id OR nx.device_id = g.device_id) AND nx.ctid < g.ctid
)
)
SELECT s.cluster_id
, s.account_id
, s.device_id
, s.wtf
FROM seed s
UNION ALL
SELECT o.cluster_id
, g.account_id
, g.device_id
, g.ctid AS wtf
FROM omg o
JOIN graph g ON (g.account_id = o.account_id OR g.device_id = o.device_id)
-- AND (g.account_id > o.account_id OR g.device_id > o.device_id)
AND g.ctid > o.wtf
-- we still need to exclude duplicates here
-- (which could occur if there are cycles in the graph)
-- , this could be done using an array
)
SELECT *
FROM omg
ORDER BY cluster_id, account_id,device_id
;
Results:
DROP SCHEMA
CREATE SCHEMA
SET
CREATE TABLE
INSERT 0 10
cluster_id | account_id | device_id
------------+------------+-----------
1 | 1 | 10
2 | 4 | 15
3 | 6 | 16
(3 rows)
cluster_id | account_id | device_id | wtf
------------+------------+-----------+--------
1 | 1 | 10 | (0,1)
1 | 1 | 11 | (0,2)
1 | 1 | 12 | (0,3)
1 | 1 | 12 | (0,3)
1 | 2 | 10 | (0,4)
1 | 3 | 11 | (0,5)
1 | 3 | 13 | (0,6)
1 | 3 | 14 | (0,7)
1 | 3 | 14 | (0,7)
2 | 4 | 15 | (0,8)
2 | 5 | 15 | (0,9)
3 | 6 | 16 | (0,10)
(12 rows)
Newer version (I added an Id column to the table)
-- for convenience :set of all adjacent nodes.
CREATE TEMP VIEW pair AS
SELECT one.id AS one
, two.id AS two
FROM graph one
JOIN graph two ON (one.account_id = two.account_id OR one.device_id = two.device_id)
AND one.id <> two.id
;
WITH RECURSIVE flood AS (
SELECT g.id, g.id AS parent_id
, 0 AS lev
, ARRAY[g.id]AS arr
FROM graph g
UNION ALL
SELECT c.id, p.parent_id AS parent_id
, 1+p.lev AS lev
, p.arr || ARRAY[c.id] AS arr
FROM graph c
JOIN flood p ON EXISTS (
SELECT * FROM pair WHERE p.id = pair.one AND c.id = pair.two)
AND p.parent_id < c.id
AND NOT p.arr @> ARRAY[c.id] -- avoid cycles/loops
)
SELECT g.*, a.parent_id
, dense_rank() over (ORDER by a.parent_id)AS group_id
FROM graph g
JOIN (SELECT id, MIN(parent_id) AS parent_id
FROM flood
GROUP BY id
) a
ON g.id = a.id
ORDER BY a.parent_id, g.id
;
New results:
CREATE VIEW
id | account_id | device_id | parent_id | group_id
----+------------+-----------+-----------+----------
1 | 1 | 10 | 1 | 1
2 | 1 | 11 | 1 | 1
3 | 1 | 12 | 1 | 1
4 | 2 | 10 | 1 | 1
5 | 3 | 11 | 1 | 1
6 | 3 | 13 | 1 | 1
7 | 3 | 14 | 1 | 1
8 | 4 | 15 | 8 | 2
9 | 5 | 15 | 8 | 2
10 | 6 | 16 | 10 | 3
(10 rows)
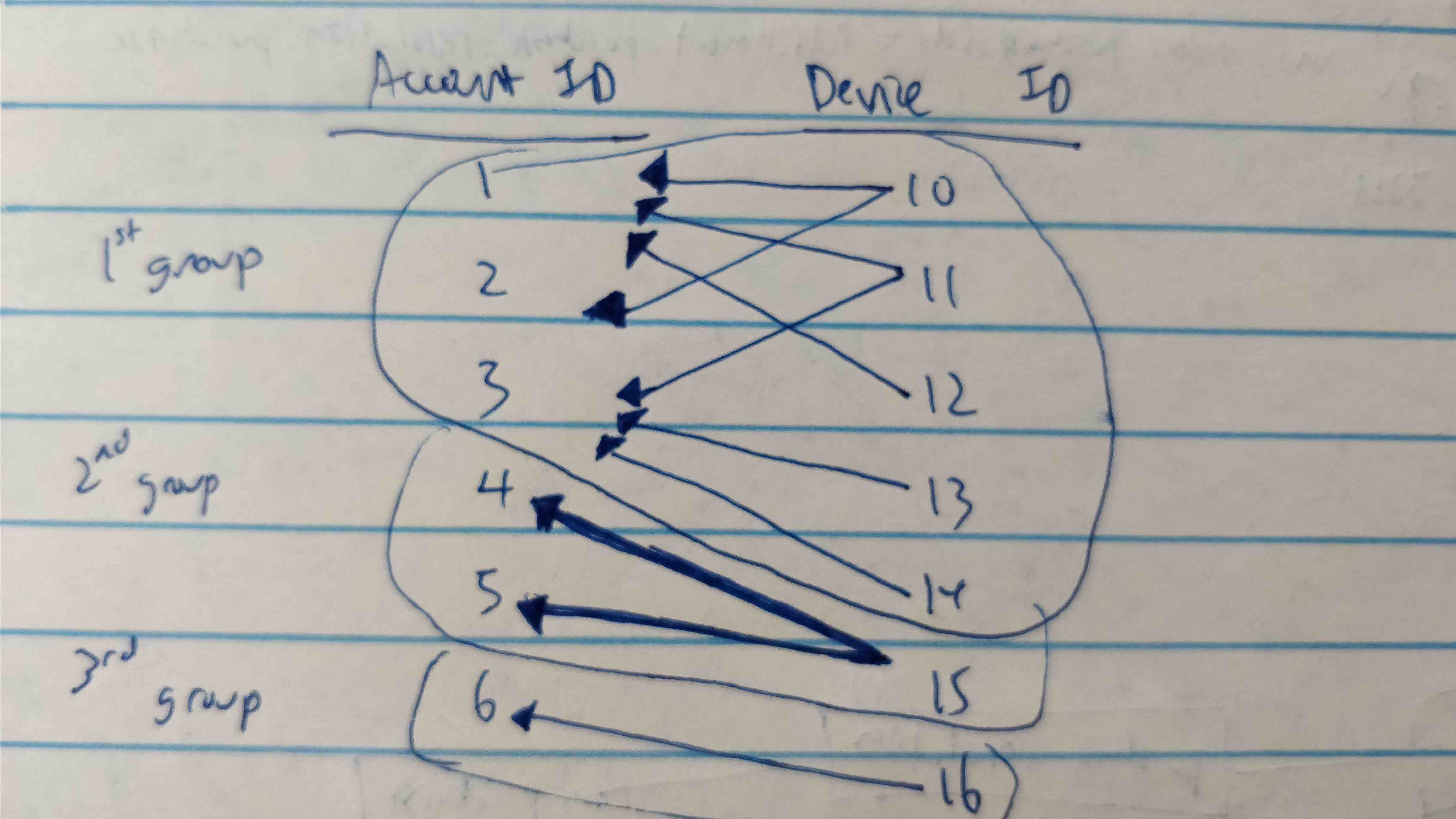
account_id1 has seendevice_ids10, 11, 12.device_id10 and 11 also have other accounts that saw them.account_id2 also sawdevice_id10 andaccount_id3 sawdevice_id11. Sinceaccount_id3 has been "touched" we also need to include all otherdevice_ids that it has seen, sodevice_id13 and 15. – BahuvrihiEXTENSION intarraywith its "intersection for arrays" + "WITH RECURSIVE" approach together can make it neat. – Celsacelsius