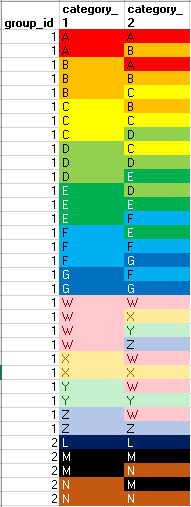
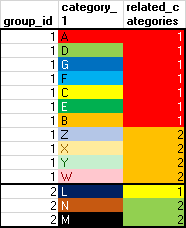
This works, but causes an "out of spool space" issue on real data.
Schema creation:
CREATE VOLATILE TABLE match_detail (
group_id bigint
, category_1 varchar(255)
, category_2 varchar(255)
) PRIMARY INDEX (group_id)
ON COMMIT PRESERVE ROWS;
INSERT INTO match_detail VALUES (1,'A','B');
INSERT INTO match_detail VALUES (1,'A','A');
INSERT INTO match_detail VALUES (1,'B','A');
INSERT INTO match_detail VALUES (1,'B','C');
INSERT INTO match_detail VALUES (1,'B','B');
INSERT INTO match_detail VALUES (1,'C','B');
INSERT INTO match_detail VALUES (1,'C','D');
INSERT INTO match_detail VALUES (1,'C','C');
INSERT INTO match_detail VALUES (1,'D','C');
INSERT INTO match_detail VALUES (1,'D','E');
INSERT INTO match_detail VALUES (1,'D','D');
INSERT INTO match_detail VALUES (1,'E','D');
INSERT INTO match_detail VALUES (1,'E','F');
INSERT INTO match_detail VALUES (1,'E','E');
INSERT INTO match_detail VALUES (1,'F','E');
INSERT INTO match_detail VALUES (1,'F','G');
INSERT INTO match_detail VALUES (1,'F','F');
INSERT INTO match_detail VALUES (1,'G','F');
INSERT INTO match_detail VALUES (1,'G','G');
INSERT INTO match_detail VALUES (1,'W','X');
INSERT INTO match_detail VALUES (1,'W','W');
INSERT INTO match_detail VALUES (1,'W','Y');
INSERT INTO match_detail VALUES (1,'W','Z');
INSERT INTO match_detail VALUES (1,'X','W');
INSERT INTO match_detail VALUES (1,'X','X');
INSERT INTO match_detail VALUES (1,'Y','W');
INSERT INTO match_detail VALUES (1,'Y','Y');
INSERT INTO match_detail VALUES (1,'Z','W');
INSERT INTO match_detail VALUES (1,'Z','Z');
INSERT INTO match_detail VALUES (2,'L','L');
INSERT INTO match_detail VALUES (2,'M','N');
INSERT INTO match_detail VALUES (2,'N','M');
INSERT INTO match_detail VALUES (2,'M','M');
INSERT INTO match_detail VALUES (2,'N','N');
Query:
WITH
related_cats AS (
SELECT
group_id
, category_1
, SUM(DISTINCT bitflag) As bitflag_total
, DENSE_RANK() OVER (
PARTITION BY
group_id
ORDER BY
group_id
, bitflag_total
) As bitflag_group
FROM bitflags
GROUP BY 1, 2
)
, bitflags As (
SELECT
DISTINCT
group_id
, category_1
, category_2
, CAST
(
2 ** (DENSE_RANK() OVER (
PARTITION BY
group_id
ORDER BY group_id
, category_2) - 1)
As bigint
) As bitflag
FROM cat_join
WHERE depth = 1
)
, RECURSIVE cat_join AS (
SELECT DISTINCT
c1.group_id
, c1.category_1
, c1.category_2
, CAST
(
n.num_categories - 1
As integer
) As max_depth
, CASE
WHEN c1.category_1 = c1.category_2 THEN 1
ELSE max_depth
END As depth
, 1 As recursion
FROM matches c1
INNER JOIN num_categories n
ON c1.group_id = n.group_id
UNION ALL
SELECT
r1.group_id
, r1.category_1
, r2.category_2
, r1.max_depth
, CASE
WHEN r1.category_1 = r1.category_2 THEN 1
WHEN r1.category_1 = r2.category_2 THEN 1
ELSE r1.depth - 1
END As cur_depth
, recursion + 1
FROM cat_join r1
INNER JOIN matches r2
ON r1.group_id = r2.group_id
AND r1.category_2 = r2.category_1
WHERE
r1.category_1 <> r2.category_2
AND r1.category_1 <> r2.category_1
AND
(r1.depth - 1) > 0
)
, matches AS (
SELECT
d.group_id
, d.category_1
, d.category_2
FROM match_detail d
GROUP BY d.group_id, d.category_1, d.category_2
)
, num_categories AS (
SELECT
u.group_id
, COUNT(DISTINCT u.category_2) AS num_categories
FROM categories u
GROUP BY u.group_id
)
, categories AS (
SELECT DISTINCT
u.group_id
, u.category_1
, u.category_2
FROM match_detail u
)
SELECT *
FROM related_cats