Default encoding on:
- Windows UTF-16.
- Linux UTF-8.
- MacOS UTF-8.
My solution Steps, includes null chars \0 (avoid truncated). Without using functions on windows.h header:
- Add Macros to detect Platform.
#if defined (_WIN32)
#define WINDOWSLIB 1
#elif defined (__ANDROID__) || defined(ANDROID)//Android
#define ANDROIDLIB 1
#elif defined (__APPLE__)//iOS, Mac OS
#define MACOSLIB 1
#elif defined (__LINUX__) || defined(__gnu_linux__) || defined(__linux__)//_Ubuntu - Fedora - Centos - RedHat
#define LINUXLIB 1
#endif
- Create conversion functions std::wstring to std::string or viceversa.
#include <locale>
#include <iostream>
#include <string>
#ifdef WINDOWSLIB
#include <Windows.h>
#endif
using namespace std::literals::string_literals;
// Convert std::wstring to std::string
std::string WidestringToString(const std::wstring& wstr, const std::string& locale)
{
if (wstr.empty())
{
return std::string();
}
size_t pos;
size_t begin = 0;
std::string ret;
size_t size;
#ifdef WINDOWSLIB
_locale_t lc = _create_locale(LC_ALL, locale.c_str());
pos = wstr.find(static_cast<wchar_t>(0), begin);
while (pos != std::wstring::npos && begin < wstr.length())
{
std::wstring segment = std::wstring(&wstr[begin], pos - begin);
_wcstombs_s_l(&size, nullptr, 0, &segment[0], _TRUNCATE, lc);
std::string converted = std::string(size, 0);
_wcstombs_s_l(&size, &converted[0], size, &segment[0], _TRUNCATE, lc);
ret.append(converted);
begin = pos + 1;
pos = wstr.find(static_cast<wchar_t>(0), begin);
}
if (begin <= wstr.length()) {
std::wstring segment = std::wstring(&wstr[begin], wstr.length() - begin);
_wcstombs_s_l(&size, nullptr, 0, &segment[0], _TRUNCATE, lc);
std::string converted = std::string(size, 0);
_wcstombs_s_l(&size, &converted[0], size, &segment[0], _TRUNCATE, lc);
converted.resize(size - 1);
ret.append(converted);
}
_free_locale(lc);
#elif defined LINUXLIB
std::string currentLocale = setlocale(LC_ALL, nullptr);
setlocale(LC_ALL, locale.c_str());
pos = wstr.find(static_cast<wchar_t>(0), begin);
while (pos != std::wstring::npos && begin < wstr.length())
{
std::wstring segment = std::wstring(&wstr[begin], pos - begin);
size = wcstombs(nullptr, segment.c_str(), 0);
std::string converted = std::string(size, 0);
wcstombs(&converted[0], segment.c_str(), converted.size());
ret.append(converted);
ret.append({ 0 });
begin = pos + 1;
pos = wstr.find(static_cast<wchar_t>(0), begin);
}
if (begin <= wstr.length()) {
std::wstring segment = std::wstring(&wstr[begin], wstr.length() - begin);
size = wcstombs(nullptr, segment.c_str(), 0);
std::string converted = std::string(size, 0);
wcstombs(&converted[0], segment.c_str(), converted.size());
ret.append(converted);
}
setlocale(LC_ALL, currentLocale.c_str());
#elif defined MACOSLIB
#endif
return ret;
}
// Convert std::string to std::wstring
std::wstring StringToWideString(const std::string& str, const std::string& locale)
{
if (str.empty())
{
return std::wstring();
}
size_t pos;
size_t begin = 0;
std::wstring ret;
size_t size;
#ifdef WINDOWSLIB
_locale_t lc = _create_locale(LC_ALL, locale.c_str());
pos = str.find(static_cast<char>(0), begin);
while (pos != std::string::npos) {
std::string segment = std::string(&str[begin], pos - begin);
std::wstring converted = std::wstring(segment.size() + 1, 0);
_mbstowcs_s_l(&size, &converted[0], converted.size(), &segment[0], _TRUNCATE, lc);
converted.resize(size - 1);
ret.append(converted);
ret.append({ 0 });
begin = pos + 1;
pos = str.find(static_cast<char>(0), begin);
}
if (begin < str.length()) {
std::string segment = std::string(&str[begin], str.length() - begin);
std::wstring converted = std::wstring(segment.size() + 1, 0);
_mbstowcs_s_l(&size, &converted[0], converted.size(), &segment[0], _TRUNCATE, lc);
converted.resize(size - 1);
ret.append(converted);
}
_free_locale(lc);
#elif defined LINUXLIB
std::string currentLocale = setlocale(LC_ALL, nullptr);
setlocale(LC_ALL, locale.c_str());
pos = str.find(static_cast<char>(0), begin);
while (pos != std::string::npos) {
std::string segment = std::string(&str[begin], pos - begin);
std::wstring converted = std::wstring(segment.size(), 0);
size = mbstowcs(&converted[0], &segment[0], converted.size());
converted.resize(size);
ret.append(converted);
ret.append({ 0 });
begin = pos + 1;
pos = str.find(static_cast<char>(0), begin);
}
if (begin < str.length()) {
std::string segment = std::string(&str[begin], str.length() - begin);
std::wstring converted = std::wstring(segment.size(), 0);
size = mbstowcs(&converted[0], &segment[0], converted.size());
converted.resize(size);
ret.append(converted);
}
setlocale(LC_ALL, currentLocale.c_str());
#elif defined MACOSLIB
#endif
return ret;
}
- Print std::string.
Check RawString Suffix.
Linux Code. Print directly std::string using std::cout.
If you have std::wstring.
1. Convert to std::string.
2. Print with std::cout.
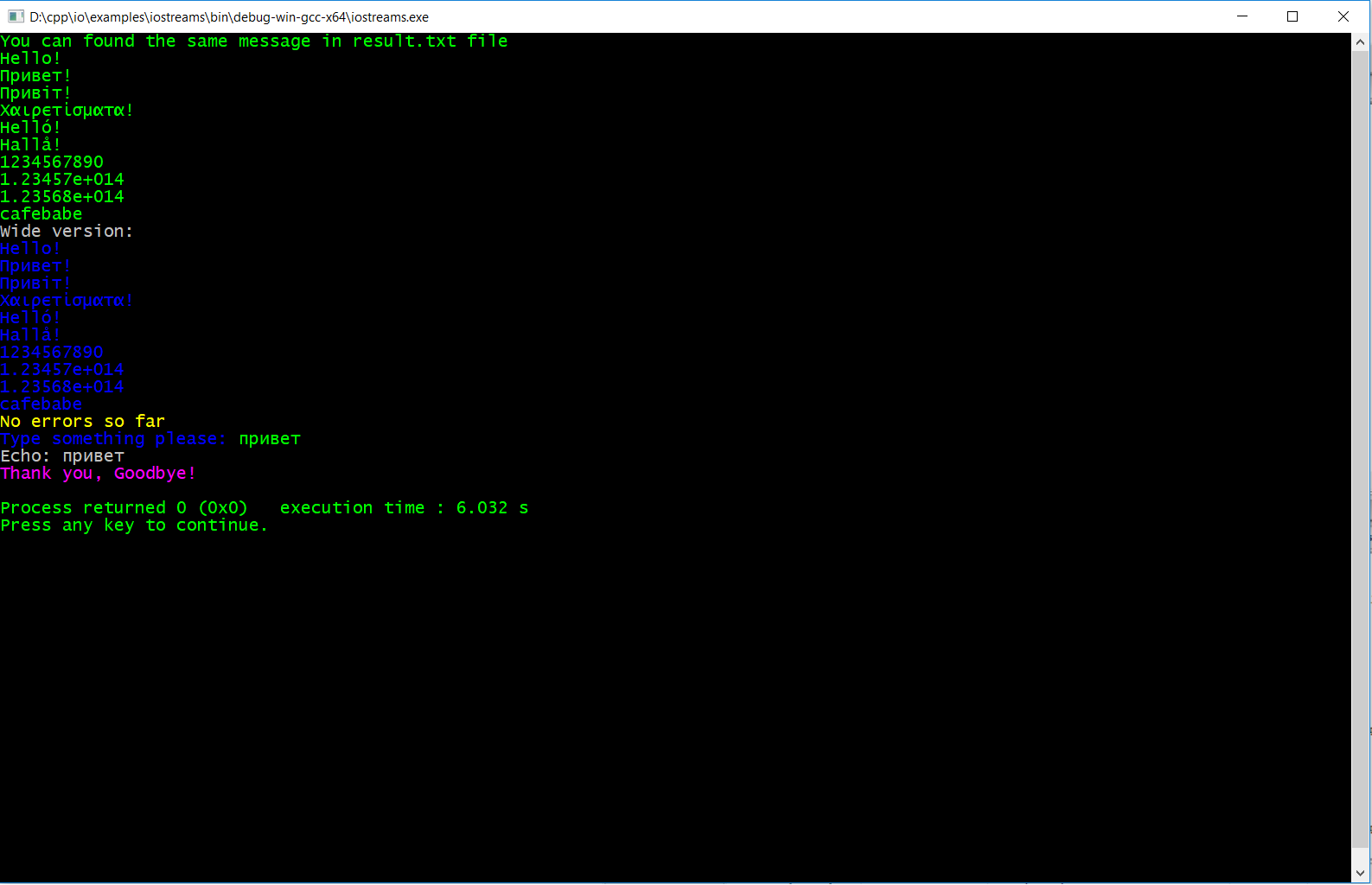
std::wstring x = L"\0\001日本ABC\0DE\0F\0G🐶\0"s;
std::string result = WidestringToString(x, "en_US.UTF-8");
std::cout << "RESULT=" << result << std::endl;
std::cout << "RESULT_SIZE=" << result.size() << std::endl;
On Windows if you need to print unicode. We need to use WriteConsole for print unicode chars from std::wstring or std::string.
void WriteUnicodeLine(const std::string& s)
{
#ifdef WINDOWSLIB
WriteUnicode(s);
std::cout << std::endl;
#elif defined LINUXLIB
std::cout << s << std::endl;
#elif defined MACOSLIB
#endif
}
void WriteUnicode(const std::string& s)
{
#ifdef WINDOWSLIB
std::wstring unicode = Insane::String::Strings::StringToWideString(s);
WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), unicode.c_str(), static_cast<DWORD>(unicode.length()), nullptr, nullptr);
#elif defined LINUXLIB
std::cout << s;
#elif defined MACOSLIB
#endif
}
void WriteUnicodeLineW(const std::wstring& ws)
{
#ifdef WINDOWSLIB
WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), ws.c_str(), static_cast<DWORD>(ws.length()), nullptr, nullptr);
std::cout << std::endl;
#elif defined LINUXLIB
std::cout << String::Strings::WidestringToString(ws)<<std::endl;
#elif defined MACOSLIB
#endif
}
void WriteUnicodeW(const std::wstring& ws)
{
#ifdef WINDOWSLIB
WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE), ws.c_str(), static_cast<DWORD>(ws.length()), nullptr, nullptr);
#elif defined LINUXLIB
std::cout << String::Strings::WidestringToString(ws);
#elif defined MACOSLIB
#endif
}
Windows Code. Using WriteLineUnicode or WriteUnicode function. Same code can be used for Linux.
std::wstring x = L"\0\001日本ABC\0DE\0F\0G🐶\0"s;
std::string result = WidestringToString(x, "en_US.UTF-8");
WriteLineUnicode(u8"RESULT" + result);
WriteLineUnicode(u8"RESULT_SIZE" + std::to_string(result.size()));
Finally on Windows. You need a powerfull and complete support for unicode chars in console.
I recommend ConEmu and set as default terminal on Windows.
Test on Microsoft Visual Studio and Jetbrains Clion.
- Tested on Microsoft Visual Studio 2017 with VC++; std=c++17. (Windows Project)
- Tested on Microsoft Visual Studio 2017 with g++; std=c++17. (Linux Project)
- Tested on Jetbrains Clion 2018.3 with g++; std=c++17. (Linux Toolchain / Remote)
QA
Q. Why you not use <codecvt> header functions and classes?.
A. Deprecate Removed or deprecated features impossible build on VC++, but no problems on g++. I prefer 0 warnings and headaches.
Q. wstring on Windows are interchan.
A. Deprecate Removed or deprecated features impossible build on VC++, but no problems on g++. I prefer 0 warnings and headaches.
Q. std ::wstring is cross platform?
A. No. std::wstring uses wchar_t elements. On Windows wchar_t size is 2 bytes, each character is stored in UTF-16 units, if character is bigger than U+FFFF, the character is represented in two UTF-16 units(2 wchar_t elements) called surrogate pairs. On Linux wchar_t size is 4 bytes each character is stored in one wchar_t element, no needed surrogate pairs. Check Standard data types on UNIX, Linux, and Windows.
Q. std ::string is cross platform?
A. Yes. std::string uses char elements. char type is guaranted that is same byte size in all compilers. char type size is 1 byte. Check Standard data types on UNIX, Linux, and Windows.

{kind=link}
WriteConsoleW-- if it doesn't work with that, then it's impossible. – Buster