The PGA tour's website has a leaderboard page page and I am trying to scrape the main table on the website for a project.
library(dplyr)
leaderboard_table <- xml2::read_html('https://www.pgatour.com/leaderboard.html') %>%
html_nodes('table') %>%
html_table()
however instead of pulling the tables, it returns this odd output...
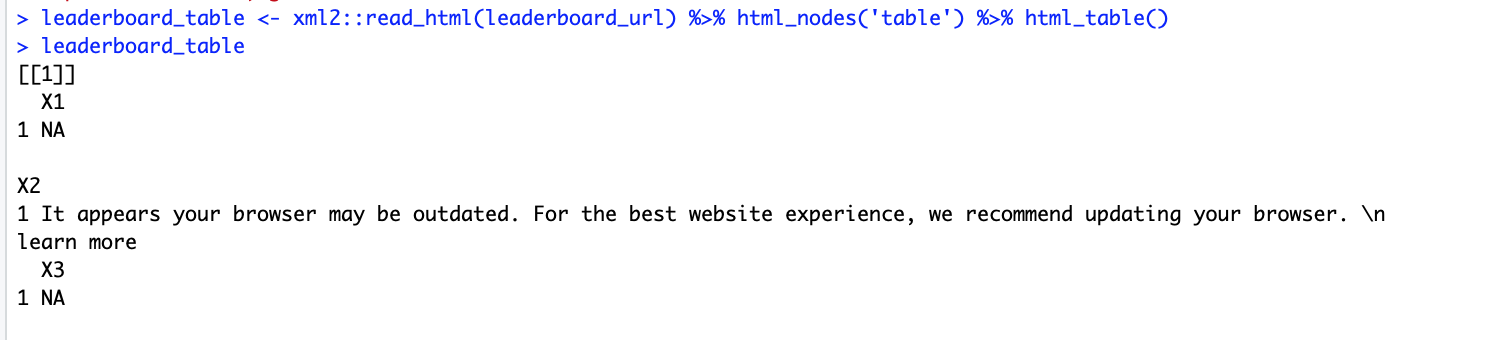
Other pages such as the schedule page scrape fine without any issues, see below. It is only the leaderboard page I am having trouble with.
schedule_url <- 'https://www.pgatour.com/tournaments/schedule.html'
schedule_table <- xml2::read_html(schedule_url) %>% html_nodes('table.table-styled') %>% html_table()
schedule_df <- schedule_table[[1]]
# this works fine
Edit Before Bounty: the below answer is a helpful start, however there is a problem. The JSON files name changes based on the round (/r/003 for 3rd round) and probably based on other aspects of the golf tournament as well. Currently there is this that i see in the elements tab:
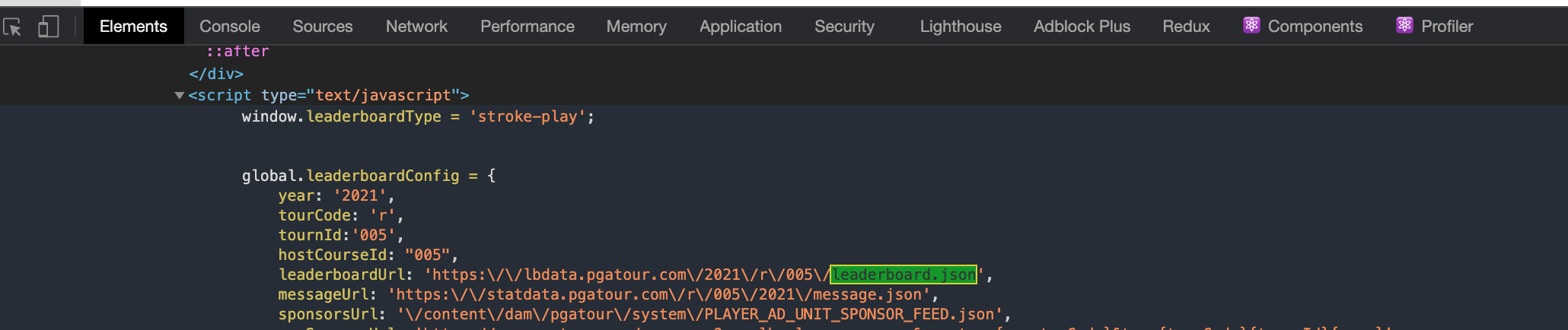
...however, using the leaderboard url link to the .json file https://lbdata.pgatour.com/2021/r/005/leaderboard.json is not helping... instead, I receive this error when using jsonlite::fromJson

Two questions then:
Is is possible to read this .JSON file into R? (perhaps it is protected in some way)? Maybe just an issue on my end, or am I missing something else in R here?
Given that the URL changes, how can I dynamically grab the URL value in R? It would be great if I could grab all of the
global.leaderboardConfigobject somehow, because that would give me access to theleaderboardUrl.
Thanks!!
rvestsolution would be great but it makes sense whyRSeleniummay be better for this, for the reasons you stated. – Flashover