Great question.
First, keep in mind that this is a simplistic example in the book. It's up to the reader to expand on this a little and imagine more complex scenarios. In all of these scenarios, further imagine that you are not the only developer on the team; instead, you are working in a large team, and communication between developers often take the form of negotiating class interfaces i.e. APIs, public methods, public attributes, database schemas. In addition, you often will have to worry about rollbacks, backwards compatibility, and synchronizing releases and deploys.
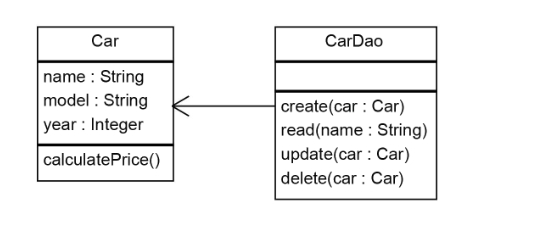
Suppose, for example, that you want to swap out the database, say, from MySQL to PostgreSQL. With SRP, you will reimplement CarDAO, change whatever dialect-specific SQL was used, and leave the Car logic intact. However, you may have to make a small change, possibly in configuration, to tell Car to use the new PostgreSQL DAO. A reasonable DI framework would make this simple.
Suppose, in another example, that you want to delegate CarDAO to another developer to integrate with memcached, so that reads, while eventually consistent, are fast. Again, this developer would not need to know anything about the business logic in Car. Instead, they only need to operate behind the CRUD methods of CarDAO, and possibly declare a few more methods in the CarDAO API with different consistency guarantees.
Suppose, in yet another example, your team hires a database engineer specializing in compliance law. In preparation for the upcoming IPO, the database engineer is tasked with keeping an audit log of all changes across all tables in the company's 35 databases. With SRP, our intrepid DBA would not have to worry about any of the business logic using any of our tables; instead, their mutation tracking magic can be deftly injected into DAOs all over, using decorators or other aspect programming techniques. (This could also be done of the other side of the SQL interface, by the way.)
Alright one last one - suppose now that a systems engineer is brought onto the team, and is tasked with sharding this data across multiple regions (data centers) in AWS. This engineer could take SRP even further and add a component whose only role is to tell us, for each ID, the home region of each entity. Each time we do a cross-region read, the new component bumps a counter; each week, an automated tool migrates data frequently read across regions into a new home region to reduce latency.
Now, let's take our imagination even further, and assume that business is booming - suddenly, you are working for a Fortune 500 company with multiple departments spanning multiple countries. Business Analysts from the Finance Department want to use your table to plot quarterly growth in auto sales in their post-IPO investor reports. Instead of giving them access to Car (because the logic used for reporting might be different from the logic used to prepare data for rendering on a web UI), you could, potentially, create a read-only interface for CarDAO with a short list of carefully curated public attributes that you now have to maintain across department boundaries. God forbid you have to rename one of these attributes: be prepared for a 3-month sunset plan and many many sad dashboards and late-night escalations. (And please don't give them direct access to the actual SQL table, because the implicit assumption will be that the entire table is the public interface.) Oops, my scars may be showing.
A corollary is that, if you need to change the business logic in Car (say, add a method that computes the lower sale price of each Tesla after an embarrassing recall), you wouldn't touch the CarDAO, since if car.brand == 'Tesla; price = price * 0.6 has nothing to do with data access.
Additional Reading: CQRS