It's complicated!
There are two elements of a snapshot:
- The data (stored as blocks)
- An index to the data
Let's say you have a totally empty Amazon EBS volume. It is smart enough to know that no blocks have been used.
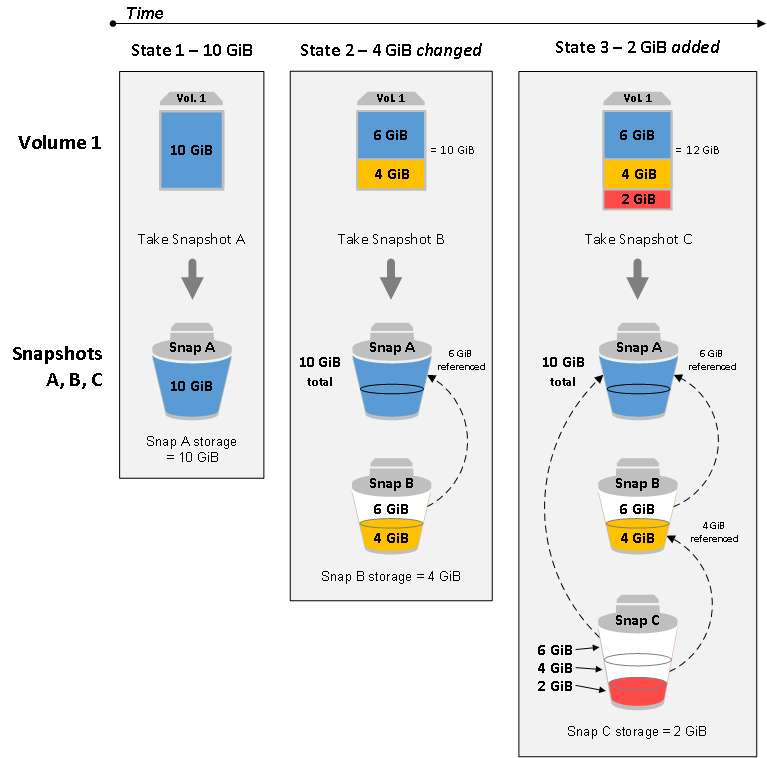
Now, let's add your 10GB of data and then create a snapshot. This will cause that 10GB of data to be copied to Amazon S3. You can't see it in S3, but Amazon EBS uses S3 for snapshots "behind the scenes". Each block that has been modified will be copied to S3 as a separate object. In addition, an 'index' will be stored that says "Snapshot #1 contains the following blocks". Therefore, the snapshot is a combination of the index and the data that is stored.
Next, let's delete some files, modify some files and add another 5GB of files. Taking another snapshot (#2) will now copy to S3 any blocks that are different to Snapshot #1, which means any blocks that have been modified or added. An index will be created that points to these new blocks, but also points to some of the blocks created in Snapshot #1 if those blocks were still present on the disk when Snapshot #2 was created. This highlights the "incremental" nature of a snapshot -- blocks that have not changed will not be copied again.
As for the blocks that were deleted, those blocks are kept in S3 because they are part of Snapshot #1, even though they are not present in Snapshot #2. This means that a new volume can be created from either Snapshot #1 or Snapshot #2.
If, however, Snapshot #1 is deleted, then any blocks only present in Snapshot #1 will also be deleted. However, any blocks that were part of both snapshots will be retained, since they are needed to restore Snapshot #2.
The simple rule is: Any data blocks that are part of an existing snapshot will be retained, so that the snapshot can be restored.
To make your mind spin even further, please note that AMIs are Snapshots with some additional metadata. So, if you launch an EC2 instance from an AMI, then the AMI is actually Snapshot #1. When you add/modify some data on that Amazon EBS volume and take a snapshot, it will copy make a copy of the blocks you changed but the snapshot will point to the AMI snapshot for most of the disk content (eg operating system).