I'm currently trying to find the bottlenecks in our message dispatcher for Akka.NET (port of java/scala actor model framework) For those interested, it can be found here: https://github.com/akkadotnet/akka.net
We seem to scale great up to 8 cores, everything seems fine so far. However, when running on larger machines, everything falls apart eventually. We have tested this on a 16 core machine, and it scales nicely up to a certain point, then suddenly, message throughput is halved.
This image is while profiling on my laptop
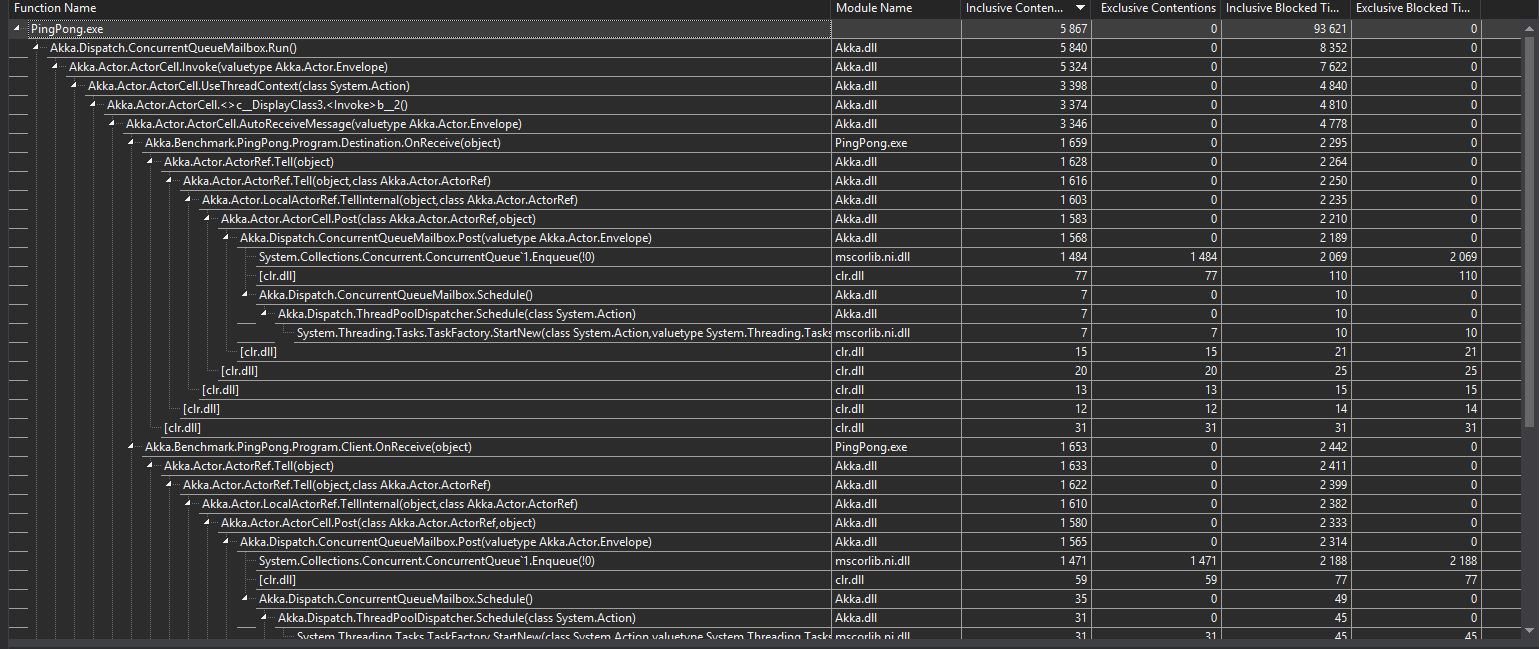 See: https://i.sstatic.net/DxboR.png for full image
See: https://i.sstatic.net/DxboR.png for full image
. Is the bottleneck the Task.Factory.StartNew, or is it the ConcurrentQueue.Enqueue ? I'm not sure I read those numbers right.
Here is a breif decription of how our message dispatcher and mailbox works:
Once a message is posted to a mailbox, the mailbox checks if it is currently processing messages. if it is processing messages, it simply let the currently running Task consume the new message.
So essentially, we post a message to a ConcurrentQueue, and the current mailbox run will find it.
if the mailbox is currently idle while the message is posted, then we schedule the mailbox using Task.Factory.StartNew(mailboxAction).
To ensure that only one task is running at any given time for a specific mailbox, we use Interlocked checks to see if the mailbox is bussy or idle. The interlock checks works, this is tested extensively so we know we don't start up multiple tasks for the same mailbox.
Any ideas what could cause throughput to break completely on the 16 core machine? The same effect does not happen on smaller machines, those stay stable at max throughput when they can not scale any more.
One thing that I have verified on the 16 core machine, is that the mailbox seems to process too fast, depleting all the messages in the actors messagequeue, which will lead a new scheduling of the mailbox once a new message arrives. That is, the consumer is faster than the producer.
ConcurrentQueuehas an implementation optimized for a low core count. In such algorithms, there's often a trade-off between scalability and performance. – Valedictorian