Because it's so easy to install on Debian stable, I decided to use PostgreSQL 9.6 to build a datawarehouse for some data I need to process. The first step is to load the data into the database with minimal transformations, mostly correcting some known formatting errors and how booleans are represented. I have checked that these corrections are efficient: writing n rows to disk takes time proportional to n.
However, bulk loading this data using PostgreSQL's COPY FROM (no matter how; \copy, or psycopg2 copy_expert, or COPY FROM '/path/to/data.csv') takes a superlinear amount of time. The asymptotic time complexity seems to somewhat better than O(exp(sqrt(n))). This is the complexity when I already:
- Set the isolation level to
READ UNCOMMITTED, and - Set the primary key constraint to
DEFERRED.
Here's what I'm seeing with one of the worst offenders, a 17M row table:
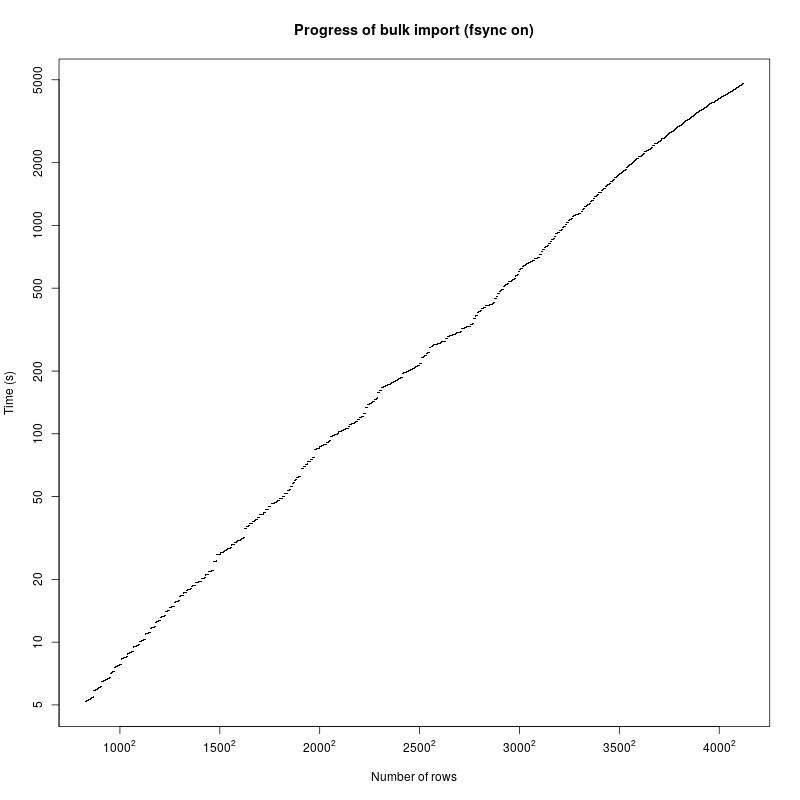
Disabling fsync speeds up the process by a factor 10, so I/O is obviously an enormous bottleneck. Other than that, however, the temporal behaviour doesn't change that much:
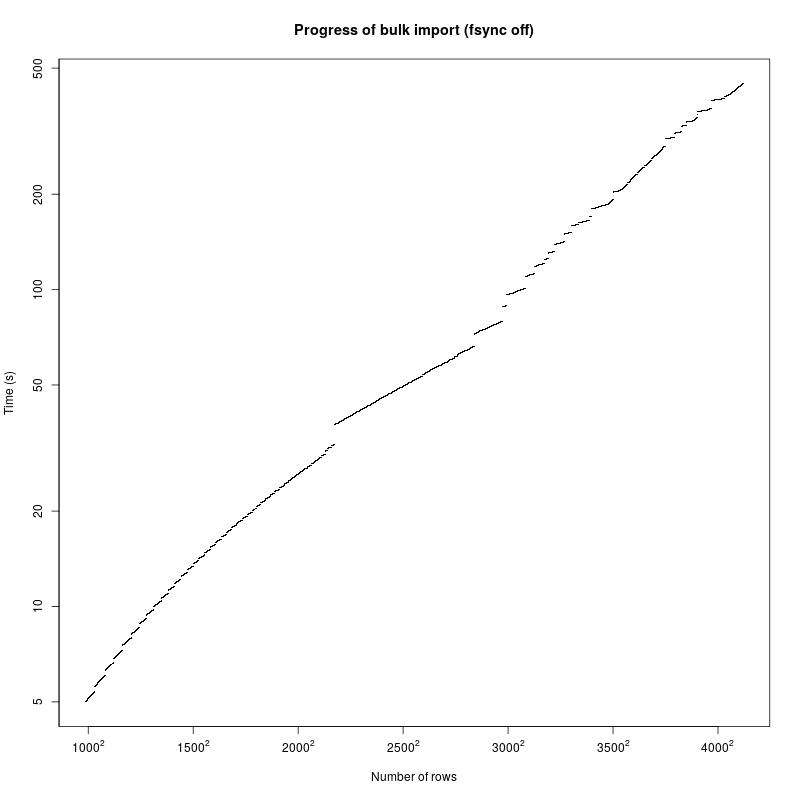
This problem disappears entirely when I use a surrogate key instead of the business key: when I use an auto-incrementing integer column as the primary key, ingestion takes Θ(n) time again, which is what I wanted. So not only do I have a perfectly valid workaround for my problem, but I also know that the complex primary key is the culprit (the business key is typically a tuple of short VARCHAR columns).
However, I would like to understand why PostgreSQL is taking so long to ingest the data when it is keyed by the business key, so that I understand my tools better. In particular, I have no idea how to debug this ingestion process, because EXPLAIN doesn't work on COPY. It could be that sorting the data into storage takes longer for compound primary keys, or that this is due to indexing, or that the primary key constraint actually is still NOT DEFERRED; if the workaround wouldn't be so effective, or undesirable for other reasons, how can I discover what's actually going on here?
insert into target_table(...) select distinct ... from temp_table where not exists(...)3) a surrogate as PK plus an (optional) UNIQUE constraint on the business_key works fine, (especially if the fat key is referenced by other tables; these could use the surrogate instead) – Submisssynchronous_commit = offandautovacuum=off(for the duration of your loading at least). Did you try batching your files into smaller chunks for COPY? Eg, 500k per file (depends on available memory, since COPY is buffering your load). – Fixed