code:
iris = datasets.load_iris()
X = iris.data
y = iris.target
clf = DecisionTreeClassifier()
clf.fit(X, y)
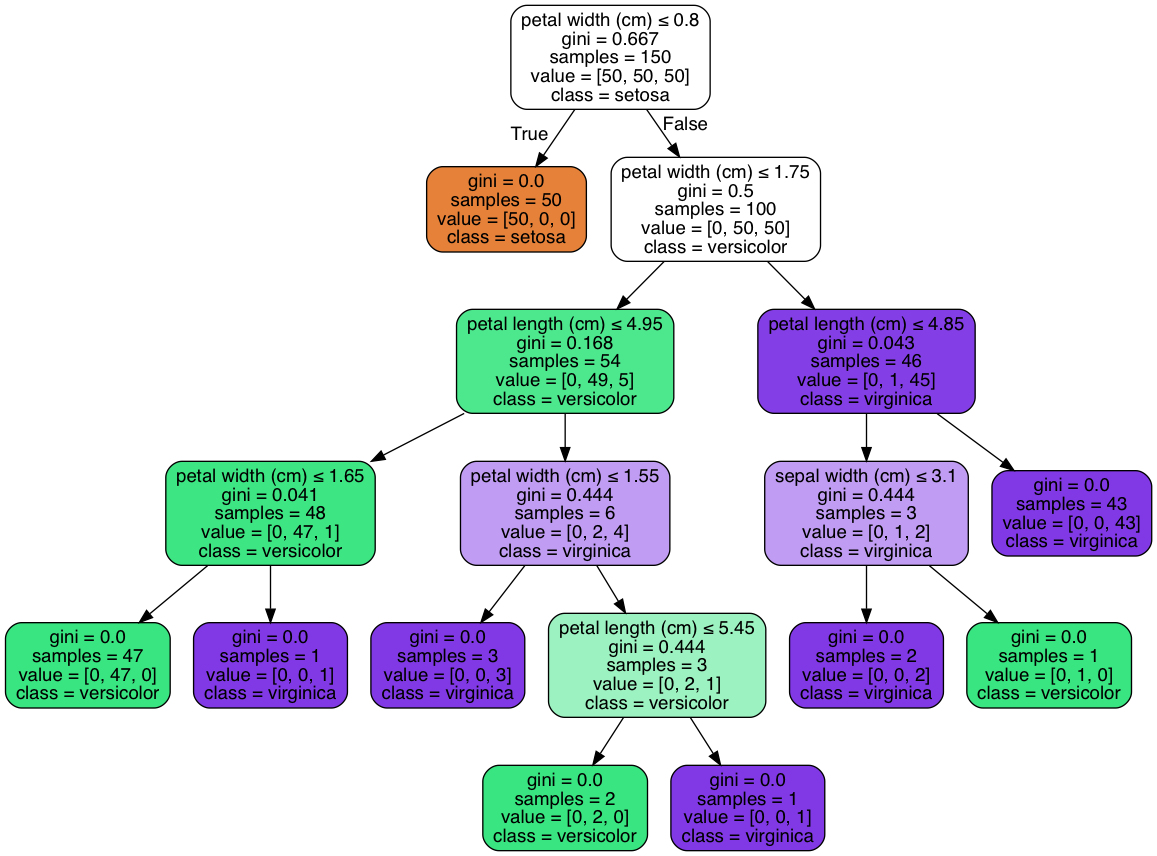
decision_tree plot:
enter image description here
We get
compute_feature_importance:[0. ,0.01333333,0.06405596,0.92261071]
Check source code:
cpdef compute_feature_importances(self, normalize=True):
"""Computes the importance of each feature (aka variable)."""
cdef Node* left
cdef Node* right
cdef Node* nodes = self.nodes
cdef Node* node = nodes
cdef Node* end_node = node + self.node_count
cdef double normalizer = 0.
cdef np.ndarray[np.float64_t, ndim=1] importances
importances = np.zeros((self.n_features,))
cdef DOUBLE_t* importance_data = <DOUBLE_t*>importances.data
with nogil:
while node != end_node:
if node.left_child != _TREE_LEAF:
# ... and node.right_child != _TREE_LEAF:
left = &nodes[node.left_child]
right = &nodes[node.right_child]
importance_data[node.feature] += (
node.weighted_n_node_samples * node.impurity -
left.weighted_n_node_samples * left.impurity -
right.weighted_n_node_samples * right.impurity)
node += 1
importances /= nodes[0].weighted_n_node_samples
if normalize:
normalizer = np.sum(importances)
if normalizer > 0.0:
# Avoid dividing by zero (e.g., when root is pure)
importances /= normalizer
return importances
Try calculate the feature importance:
print("sepal length (cm)",0)
print("sepal width (cm)",(3*0.444-(0+0)))
print("petal length (cm)",(54* 0.168 - (48*0.041+6*0.444)) +(46*0.043 -(0+3*0.444)) + (3*0.444-(0+0)))
print("petal width (cm)",(150* 0.667 - (0+100*0.5)) +(100*0.5-(54*0.168+46*0.043))+(6*0.444 -(0+3*0.444)) + (48*0.041-(0+0)))
We get feature_importance: np.array([0,1.332,6.418,92.30]).
After normalized, we get array ([0., 0.01331334, 0.06414793, 0.92253873]),this is same as clf.feature_importances_.
Be careful all classes are supposed to have weight one.
{kind=link}