(The following is a kind of a "theoretical MCVE" of the kinds of complexity I'm encountering in organizing source code I'm working on. You can treat it as a concrete problem and that would be good, or you can refer to the general concerns it brings up and suggest how to address them.)
Suppose I have modules of code A, B, C and D. A depends on B,C,D; B depends on C; C, D don't depend on other modules. (I use the term "modules" loosely, so no nitpicking here please).
Additionally, in all of A,B,C,D, a few identical header files are used, and perhaps even a compiled object, and it doesn't make sense to put these together and form a fifth module because it would be too small and useless. Let's have foo.h be one of the files in that category.
While all of these modules are kept within a single monolithic code repository, all is good. There's exactly one copy of everything; no linker conflicts between objects compiled with the same functions etc.
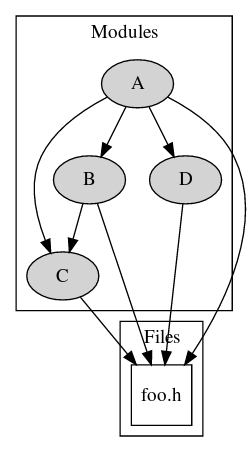
The question is: How do I make each of B, C, D into a version-managed repository, so that:
- Each of them can be built with only the presence of the modules it depends on (either as submodules/subrepositories or some other way); and
- I do not need to make sure and manually maintain/update separate versions of the same files, or make carry-over commits from one library to the next (except perhaps changing the pointed-to revision); and
- When everything is built together (i.e. when building A), the build does not involve qudaruple copies of
foo.hand a double copy of C (once for A and once for B) - which I would probably always have to make sure and keep perfectly synchronized.
Note that when I have a bit more time I'll edit this to make the question more concrete (even though I kind of like the broad question). I will say that in my specific case the code is modern C++, CUDA, some bash scripts and CMake modules. So a Java-oriented solution would not do.