I seem to have a memory leak in my Google App Engine app but I cannot figure out why.
After narrowing down the lines of code responsible, I have reduced the problem to a simple cron job that run regularly and all it does is load some entities using a query.
I include the memory usage using logging.info(runtime.memory_usage()) and I can see that the memory usage increases from one call to the next until it exceeds the soft private memory limit.
Below is the code I have used:
class User(ndb.Model):
_use_cache = False
_use_memcache = False
name = ndb.StringProperty(required=True)
...[OTHER_PROPERTIES]...
class TestCron(webapp2.RequestHandler):
def get(self):
is_cron = self.request.headers.get('X-AppEngine-Cron') == 'true'
if is_cron:
logging.info("Memory before keys:")
logging.info(runtime.memory_usage())
keys = models.User.query().fetch(1000, keys_only=True)
logging.info("Memory before get_multi:")
logging.info(runtime.memory_usage())
user_list = ndb.get_multi(keys)
logging.info("Memory after:")
logging.info(runtime.memory_usage())
logging.info(len(user_list))
app = webapp2.WSGIApplication([
('/test_cron', TestCron)
], debug=True)
And in cron.yaml I have:
- description: Test cron
url: /test_cron
schedule: every 1 mins from 00:00 to 23:00
When running this task every minute, every 2 iterations it has to restart a new instance. The first time it starts with 36mb, and on completion it says
This request caused a new process to be started for your application, and thus caused your application code to be loaded for the first time. This request may thus take longer and use more CPU than a typical request for your application.
But on the second execution it starts with 107mb of memory used (meaning it didn't clear the memory from the previous iteration?), and it exceeds the soft private memory limit and terminates the process by saying:
Exceeded soft private memory limit of 128 MB with 134 MB after servicing 6 requests total After handling this request, the process that handled this request was found to be using too much memory and was terminated. This is likely to cause a new process to be used for the next request to your application. If you see this message frequently, you may have a memory leak in your application.
Below is the full output of both logs:
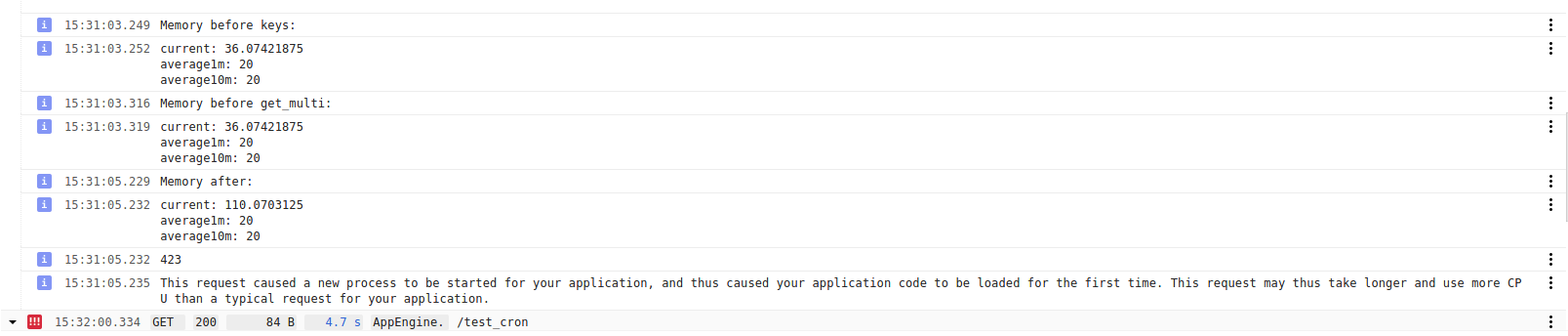
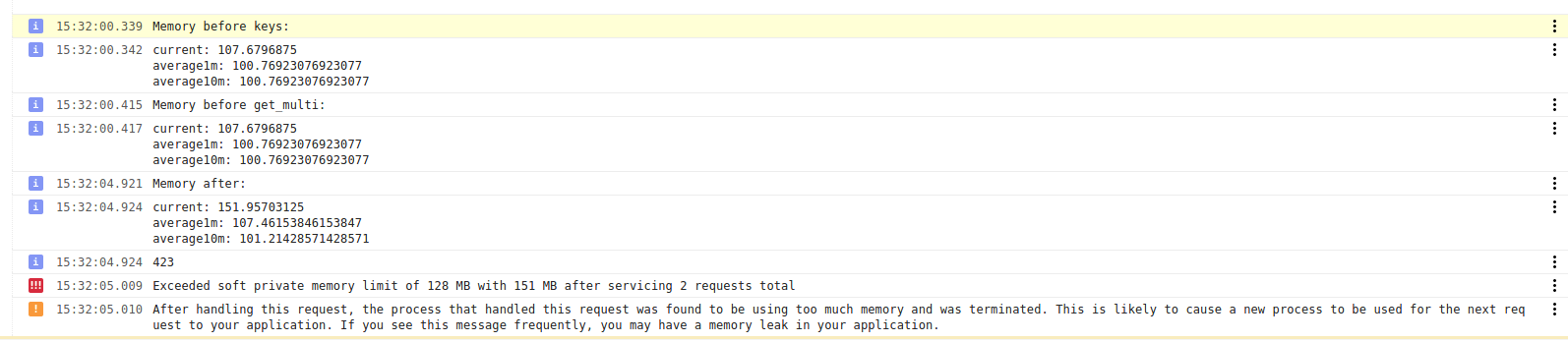
The output just alternates between these 2 logs. Note that I have disabled the cache in the definition of the model, so shouldn't the memory usage be reset at every function call?
38.66 -> 87.132nd call:88.63 -> 134.19 -> memory error2) 1st call:37.27 -> 84.682nd call:87.89 -> 136.57 -> memory errorI then tried to reduce the frequency to every 5 mins as you suggested and there wasn't much difference: 1) 1st call:37.95 -> 84.652nd pass:87.81 -> 133.38 -> memory error2) 1st pass:38.15 -> 87.612nd pass:87.73 -> 136.43 -> memory error– Basifixed38.58 -> 84.43;87.9 -> 133.2;136.58 -> 138.37;138.36 -> 138.39;138.39 -> 138.39We can see that it starts with the same memory usage and keeps increasing, but this time it stabilises below the limit and stays there. Looking at the logs later on (I left the cron job running for a while) I noticed that although sometimes it goes above 200mb or even runs out of memory (same message as with F1), most of the time it works fine. – Basifixedgc.collect()at the beginning and at the end of the cron function and I have also set the instance type to F1 (limit at 128mb), and now the function manages to run correctly almost at every run. Still, from time to time it sees its memory usage spike and the error comes back, so there still is something strange. – Basifixed