From what has been gathered from the question and the comments, there appears to be a few viable solutions.
Solution 1
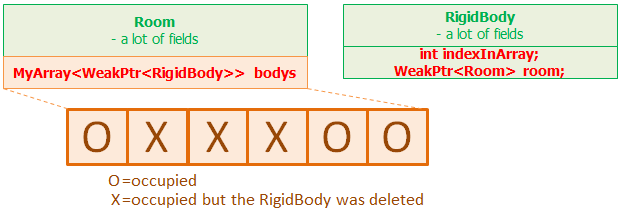
The first possible solution that others have been pointing out in the comments would be using a free index slot before appending to the array. This would involve each Room or object holding an array RigidBody to have a list of free indexes, std::forward_list or std::vector would be good for this. Then, you can add a RigidBody by first checking if there an available slot from the list. If there is, you pop off that index from the list, otherwise you append to the array. Removing a RigidBody simply involves pushing that freed up index to the list of available slots. Now, this solution would require that each RigidBody contains a list of parent and index pairs. That way, when the RigidBody is destroyed you simply notify each parent to free up the index the object was using.
Advantages
- Could be a bit odd to implement.
- Adding and removing is
O(1).
- Iteration speed is generally good.
Disadvantages
- Uses a decent amount of memory.
- The array will be growing.
- Have to use a unique key per parent.
Solution 2
There is also another similar type of solution that was discussed in the comments. However, instead of a RigidBody having multiple indexes for each parents, it has one unique ID that acts as an index. This unique ID should have a known range of minimum and maximum values. Then, each parent would allocate enough space to house the maximum amount of IDs and RigidBodies. The destruction and removal of a RigidBody is simple since you have to simply pass at ID/index to each registered parent. In addition, you could use a list to keep track of free ID's.
Advantages
- Array will not be growing during runtime.
- Adding and removing is
O(1).
- Less keys and indexes.
- Same key/index for all parents.
- Great if the array is going to be mostly filled.
Disadvantages
- Uses a lot of memory.
- Iteration will be inefficient if the array is mostly empty.
Solution 3
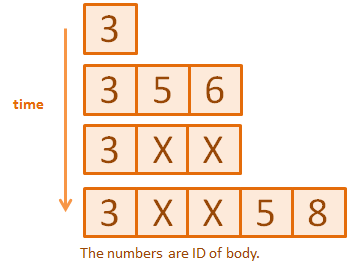
The periodic cleanup idea you suggested could work. However, it is likely that cleaning up all of the arrays in one-go could cost a lot of time. Hence, a possible adjustment would be to partially clear the array at the end of every timestep. That adjustment would require you having to store an index of where you last left off. To which, you would use that index to continue clearing sections of the array. Once the array has been fully cleared you can reset that index to 0 and start over. This solution and adjustment would only work if the rate you are removing bodies is usually greater than the rate of adding bodies.
Advantages
- Easy to implement.
- Easy to tune and adjust.
Disadvantages
- Could fail depending on the rate of items being added and removed.
- Could use more memory than necessary.
Solution 4
Another solution would involve using the address or ID of the rigid body to 'hash' or it into an array of vectors. This array of vectors could be accomplished by using a prime number to act as the size of the array. Then, we can use the RigidBodies ID or address and modulo that with the size of the array to place it into a vector. This makes erasing faster than a normal vector. In addition, it uses less memory than a massive static array of slots. Iterating over this structure would involve iterating over each bucket/vector. Or you can create a custom iterator that does this for you.
Basic Implementation of Structure
namespace {
template<typename Int>
constexpr bool isPrime(Int num, Int test = 2) {
return (test * test > num ? true : (num % test == 0 ? false : isPrime(num, test + 1)));
}
//Buckets must be a size
template<typename data_t, std::size_t PRIME_SIZE, typename = typename std::enable_if<isPrime(PRIME_SIZE)>::type>
class BucketVector
{
public:
constexpr static auto SIZE = PRIME_SIZE;
template<bool is_const>
using BucketIteratorBase = typename std::iterator<std::bidirectional_iterator_tag, typename std::conditional<is_const, const data_t, data_t>::type>;
using uint_t = std::uintptr_t;
using BucketType = std::vector<data_t>;
template<bool is_const>
class BucketIterator : public BucketIteratorBase<is_const> {
public:
using Base = BucketIteratorBase<is_const>;
using BucketOwner = BucketVector<data_t, PRIME_SIZE>;
using typename Base::pointer;
using typename Base::reference;
using typename Base::value_type;
friend class BucketIterator<!is_const>;
std::size_t m_bucket;
pointer m_value;
BucketOwner* m_owner;
public:
BucketIterator(std::size_t bucket, pointer value, BucketOwner* owner)
: m_bucket(bucket),
m_value(value),
m_owner(owner) {
//validateIterator();
}
~BucketIterator() {
}
template<bool value, typename = typename std::enable_if<!value || (value == is_const)>::type>
BucketIterator(const BucketIterator<value>& iterator)
: m_bucket(iterator.m_bucket),
m_value(iterator.m_value),
m_owner(iterator.m_owner) {
}
template<bool value, typename = typename std::enable_if<!value || (value == is_const)>::type>
BucketIterator(BucketIterator<value>&& iterator)
: m_bucket(std::move(iterator.m_bucket)),
m_value(std::move(iterator.m_value)),
m_owner(std::move(iterator.m_owner)) {
}
template<bool value, typename = typename std::enable_if<!value || (value == is_const)>::type>
BucketIterator& operator=(BucketIterator<value>&& iterator) {
m_bucket = std::move(iterator.m_bucket);
m_value = std::move(iterator.m_value);
m_owner = std::move(iterator.m_owner);
return *this;
}
template<bool value, typename = typename std::enable_if<!value || (value == is_const)>::type>
BucketIterator& operator=(const BucketIterator<value>& iterator) {
m_bucket = iterator.m_bucket;
m_value = iterator.m_value;
m_owner = iterator.m_owner;
return *this;
}
BucketIterator& operator++() {
++m_value;
forwardValidate();
return *this;
}
BucketIterator operator++(int) {
BucketIterator copy(*this);
++(*this);
return copy;
}
BucketIterator& operator--() {
backwardValidate();
--m_value;
return *this;
}
BucketIterator operator--(int) {
BucketIterator copy(*this);
--(*this);
return copy;
}
reference operator*() const {
return *m_value;
}
pointer operator->() const {
return m_value;
}
template<bool value>
bool operator==(const BucketIterator<value>& iterator) const {
return m_bucket == iterator.m_bucket && m_owner == iterator.m_owner && m_value == iterator.m_value;
}
template<bool value>
bool operator!=(const BucketIterator<value>& iterator) const {
return !(this->operator==(iterator));
}
BucketOwner* getSystem() const {
return m_owner;
}
inline void backwardValidate() {
while (m_value == m_owner->m_buckets[m_bucket].data() && m_bucket != 0) {
--m_bucket;
m_value = m_owner->m_buckets[m_bucket].data() + m_owner->m_buckets[m_bucket].size();
}
}
inline void forwardValidate() {
while (m_value == (m_owner->m_buckets[m_bucket].data() + m_owner->m_buckets[m_bucket].size()) && m_bucket != SIZE - 1) {
m_value = m_owner->m_buckets[++m_bucket].data();
}
}
};
using iterator = BucketIterator<false>;
using const_iterator = BucketIterator<true>;
friend class BucketIterator<false>;
friend class BucketIterator<true>;
private:
std::array<BucketType, SIZE> m_buckets;
std::size_t m_size;
public:
BucketVector()
: m_size(0) {
}
~BucketVector() {
}
BucketVector(const BucketVector&) = default;
BucketVector(BucketVector&&) = default;
BucketVector& operator=(const BucketVector&) = default;
BucketVector& operator=(BucketVector&&) = default;
data_t& operator[](std::size_t index) {
const auto bucketIndex = findBucketIndex(index);
return m_buckets[bucketIndex.first][bucketIndex.second];
}
const data_t& operator[](std::size_t index) const {
return static_cast<BucketVector*>(this)->operator[](index);
}
data_t& at(std::size_t index) {
if (index >= m_size) {
throw std::out_of_range("BucketVector::at index out of range");
}
return this->operator[](index);
}
const data_t& at(std::size_t index) const {
return static_cast<BucketVector*>(this)->at(index);
}
void erase(const_iterator iter) {
auto& bucket = m_buckets[iter.m_bucket];
std::size_t index = iter.m_value - bucket.data();
bucket[index] = bucket.back();
bucket.pop_back();
--m_size;
}
void push_back(uint_t id, const data_t& data) {
const auto slot = get_slot(id);
m_buckets[slot].push_back(data);
++m_size;
}
void push_back(uint_t id, data_t&& data) {
const auto slot = get_slot(id);
m_buckets[slot].push_back(std::move(data));
++m_size;
}
template<typename... args>
void emplace_back(uint_t id, args&&... parameters) {
const auto slot = get_slot(id);
m_buckets[slot].emplace_back(std::forward<args>(parameters)...);
++m_size;
}
void pop_back(uint_t index) {
const auto slot = get_slot(index);
m_buckets[slot].pop_back();
--m_size;
}
void pop_front(uint_t index) {
const auto slot = get_slot(index);
m_buckets[slot].pop_front();
--m_size;
}
void reserve(std::size_t size) {
const std::size_t slotSize = size / SIZE + 1;
for (auto& bucket : m_buckets) {
bucket.reserve(slotSize);
}
}
void clear() {
for (auto& bucket : m_buckets) {
bucket.clear();
}
}
bool empty() const {
return m_size != 0;
}
std::size_t size() const {
return m_size;
}
iterator find(uint_t index, const data_t& value) {
const std::size_t slot = get_slot(index);
auto& bucket = m_buckets[slot];
for (auto it = bucket.begin(), end = bucket.end(); it != end; ++it) {
if (*it == value) {
return { slot, &(*it), this };
}
}
return end();
}
template<typename fn_t>
iterator find(uint_t index, const fn_t& fn) {
const std::size_t slot = get_slot(index);
auto& bucket = m_buckets[slot];
for (auto it = bucket.begin(), end = bucket.end(); it != end; ++it) {
if (fn(*it)) {
return { slot, &(*it), this };
}
}
return end();
}
const_iterator find(uint_t index, const data_t& value) const {
return cfind(index, value);
}
const_iterator cfind(uint_t index, const data_t& value) const {
return static_cast<BucketVector*>(this)->find(index, value);
}
iterator begin(uint_t index = 0) {
auto bucketIndex = findBucketIndex(index);
iterator it{ bucketIndex.first, m_buckets[bucketIndex.first].data() + bucketIndex.second, this };
it.forwardValidate();
return it;
}
iterator end(uint_t index = 0) {
iterator it{ SIZE - 1, m_buckets.back().data() + m_buckets.back().size(), this };
return it;
}
const_iterator begin(uint_t index = 0) const {
auto bucketIndex = findBucketIndex(index);
const_iterator it{ bucketIndex.first, m_buckets[bucketIndex.first].data() + bucketIndex.second, this };
it.forwardValidate();
return it;
}
const_iterator end(uint_t index = 0) const {
const_iterator it{ SIZE - 1, m_buckets.back().data() + m_buckets.back().size(), this };
return it;
}
std::size_t get_slot(uint_t id) {
return id % SIZE;
}
private:
inline std::pair<std::size_t, std::size_t> findBucketIndex(std::size_t index) {
std::size_t bucket = 0;
std::size_t count = 0;
while (index >= m_buckets[bucket].size() + count) {
count += m_buckets[bucket].size();
++bucket;
}
return { bucket, index - count };
}
};
}
Advantages
- Appending is
O(1).
- Use's less memory than Solution 1 and 2.
- Can be used to quickly find out if a
RigidBody belongs to a parent.
- Erasing is fast for the size of vector you are going to use.
- Iteration is faster than Solution's 1 and 2 if the array is more than 50% empty.
Disadvantages
- Erasing is fast but not as fast as Solution's 1 and 2.
- Vectors will grow.
- Iteration is slower than Solution's 1 and 2 if the array is more than 50% full.
Basic Benchmark Program
You can use this program to test various inputs such as size and amount of values to remove to see the performance.
#include <chrono>
#include <iostream>
#include <vector>
#include <algorithm>
#include <random>
#include <set>
#include <iomanip>
#include <unordered_set>
#include <array>
#include <vector>
#include <iterator>
#include <type_traits>
template<typename mclock_t = typename std::conditional<std::chrono::high_resolution_clock::is_steady, std::chrono::high_resolution_clock, std::chrono::steady_clock>::type>
class Benchmarker {
public:
using ClockType = mclock_t;
using TimePoint = std::chrono::time_point<ClockType>;
private:
TimePoint m_start;
TimePoint m_end;
bool m_running;
public:
Benchmarker(bool run = false) {
m_running = run;
if (m_running) {
start();
}
}
Benchmarker& start() {
m_start = ClockType::now();
m_running = true;
return *this;
}
Benchmarker& stop() {
m_end = ClockType::now();
m_running = false;
return *this;
}
template<typename T = std::chrono::microseconds>
Benchmarker& printDuration(std::ostream& out) {
out << std::chrono::duration_cast<T>(m_end - m_start).count();
return *this;
}
template<typename T = std::chrono::microseconds>
long long getDurationCount() {
return std::chrono::duration_cast<T>(m_end - m_start).count();
}
friend std::ostream& operator<<(std::ostream& out, Benchmarker& benchmarker) {
out << std::chrono::duration_cast<std::chrono::microseconds>(benchmarker.m_end - benchmarker.m_start).count();
return out;
}
TimePoint getDuration() {
return m_end - m_start;
}
TimePoint getStartTime() {
return m_start;
}
TimePoint getEndTime() {
return m_end;
}
bool isRunning() {
return m_running;
}
};
namespace {
template<typename Int>
constexpr bool isPrime(Int num, Int test = 2) {
return (test * test > num ? true : (num % test == 0 ? false : isPrime(num, test + 1)));
}
//Buckets must be a size
template<typename data_t, std::size_t PRIME_SIZE, typename = typename std::enable_if<isPrime(PRIME_SIZE)>::type>
class BucketVector
{
public:
constexpr static auto SIZE = PRIME_SIZE;
template<bool is_const>
using BucketIteratorBase = typename std::iterator<std::bidirectional_iterator_tag, typename std::conditional<is_const, const data_t, data_t>::type>;
using uint_t = std::uintptr_t;
using BucketType = std::vector<data_t>;
template<bool is_const>
class BucketIterator : public BucketIteratorBase<is_const> {
public:
using Base = BucketIteratorBase<is_const>;
using BucketOwner = BucketVector<data_t, PRIME_SIZE>;
using typename Base::pointer;
using typename Base::reference;
using typename Base::value_type;
friend class BucketIterator<!is_const>;
std::size_t m_bucket;
pointer m_value;
BucketOwner* m_owner;
public:
BucketIterator(std::size_t bucket, pointer value, BucketOwner* owner)
: m_bucket(bucket),
m_value(value),
m_owner(owner) {
//validateIterator();
}
~BucketIterator() {
}
template<bool value, typename = typename std::enable_if<!value || (value == is_const)>::type>
BucketIterator(const BucketIterator<value>& iterator)
: m_bucket(iterator.m_bucket),
m_value(iterator.m_value),
m_owner(iterator.m_owner) {
}
template<bool value, typename = typename std::enable_if<!value || (value == is_const)>::type>
BucketIterator(BucketIterator<value>&& iterator)
: m_bucket(std::move(iterator.m_bucket)),
m_value(std::move(iterator.m_value)),
m_owner(std::move(iterator.m_owner)) {
}
template<bool value, typename = typename std::enable_if<!value || (value == is_const)>::type>
BucketIterator& operator=(BucketIterator<value>&& iterator) {
m_bucket = std::move(iterator.m_bucket);
m_value = std::move(iterator.m_value);
m_owner = std::move(iterator.m_owner);
return *this;
}
template<bool value, typename = typename std::enable_if<!value || (value == is_const)>::type>
BucketIterator& operator=(const BucketIterator<value>& iterator) {
m_bucket = iterator.m_bucket;
m_value = iterator.m_value;
m_owner = iterator.m_owner;
return *this;
}
BucketIterator& operator++() {
++m_value;
forwardValidate();
return *this;
}
BucketIterator operator++(int) {
BucketIterator copy(*this);
++(*this);
return copy;
}
BucketIterator& operator--() {
backwardValidate();
--m_value;
return *this;
}
BucketIterator operator--(int) {
BucketIterator copy(*this);
--(*this);
return copy;
}
reference operator*() const {
return *m_value;
}
pointer operator->() const {
return m_value;
}
template<bool value>
bool operator==(const BucketIterator<value>& iterator) const {
return m_bucket == iterator.m_bucket && m_owner == iterator.m_owner && m_value == iterator.m_value;
}
template<bool value>
bool operator!=(const BucketIterator<value>& iterator) const {
return !(this->operator==(iterator));
}
BucketOwner* getSystem() const {
return m_owner;
}
inline void backwardValidate() {
while (m_value == m_owner->m_buckets[m_bucket].data() && m_bucket != 0) {
--m_bucket;
m_value = m_owner->m_buckets[m_bucket].data() + m_owner->m_buckets[m_bucket].size();
}
}
inline void forwardValidate() {
while (m_value == (m_owner->m_buckets[m_bucket].data() + m_owner->m_buckets[m_bucket].size()) && m_bucket != SIZE - 1) {
m_value = m_owner->m_buckets[++m_bucket].data();
}
}
};
using iterator = BucketIterator<false>;
using const_iterator = BucketIterator<true>;
friend class BucketIterator<false>;
friend class BucketIterator<true>;
private:
std::array<BucketType, SIZE> m_buckets;
std::size_t m_size;
public:
BucketVector()
: m_size(0) {
}
~BucketVector() {
}
BucketVector(const BucketVector&) = default;
BucketVector(BucketVector&&) = default;
BucketVector& operator=(const BucketVector&) = default;
BucketVector& operator=(BucketVector&&) = default;
data_t& operator[](std::size_t index) {
const auto bucketIndex = findBucketIndex(index);
return m_buckets[bucketIndex.first][bucketIndex.second];
}
const data_t& operator[](std::size_t index) const {
return static_cast<BucketVector*>(this)->operator[](index);
}
data_t& at(std::size_t index) {
if (index >= m_size) {
throw std::out_of_range("BucketVector::at index out of range");
}
return this->operator[](index);
}
const data_t& at(std::size_t index) const {
return static_cast<BucketVector*>(this)->at(index);
}
void erase(const_iterator iter) {
auto& bucket = m_buckets[iter.m_bucket];
std::size_t index = iter.m_value - bucket.data();
bucket[index] = bucket.back();
bucket.pop_back();
--m_size;
}
void push_back(uint_t id, const data_t& data) {
const auto slot = get_slot(id);
m_buckets[slot].push_back(data);
++m_size;
}
void push_back(uint_t id, data_t&& data) {
const auto slot = get_slot(id);
m_buckets[slot].push_back(std::move(data));
++m_size;
}
template<typename... args>
void emplace_back(uint_t id, args&&... parameters) {
const auto slot = get_slot(id);
m_buckets[slot].emplace_back(std::forward<args>(parameters)...);
++m_size;
}
void pop_back(uint_t index) {
const auto slot = get_slot(index);
m_buckets[slot].pop_back();
--m_size;
}
void pop_front(uint_t index) {
const auto slot = get_slot(index);
m_buckets[slot].pop_front();
--m_size;
}
void reserve(std::size_t size) {
const std::size_t slotSize = size / SIZE + 1;
for (auto& bucket : m_buckets) {
bucket.reserve(slotSize);
}
}
void clear() {
for (auto& bucket : m_buckets) {
bucket.clear();
}
}
bool empty() const {
return m_size != 0;
}
std::size_t size() const {
return m_size;
}
iterator find(uint_t index, const data_t& value) {
const std::size_t slot = get_slot(index);
auto& bucket = m_buckets[slot];
for (auto it = bucket.begin(), end = bucket.end(); it != end; ++it) {
if (*it == value) {
return { slot, &(*it), this };
}
}
return end();
}
template<typename fn_t>
iterator find(uint_t index, const fn_t& fn) {
const std::size_t slot = get_slot(index);
auto& bucket = m_buckets[slot];
for (auto it = bucket.begin(), end = bucket.end(); it != end; ++it) {
if (fn(*it)) {
return { slot, &(*it), this };
}
}
return end();
}
const_iterator find(uint_t index, const data_t& value) const {
return cfind(index, value);
}
const_iterator cfind(uint_t index, const data_t& value) const {
return static_cast<BucketVector*>(this)->find(index, value);
}
iterator begin(uint_t index = 0) {
auto bucketIndex = findBucketIndex(index);
iterator it{ bucketIndex.first, m_buckets[bucketIndex.first].data() + bucketIndex.second, this };
it.forwardValidate();
return it;
}
iterator end(uint_t index = 0) {
iterator it{ SIZE - 1, m_buckets.back().data() + m_buckets.back().size(), this };
return it;
}
const_iterator begin(uint_t index = 0) const {
auto bucketIndex = findBucketIndex(index);
const_iterator it{ bucketIndex.first, m_buckets[bucketIndex.first].data() + bucketIndex.second, this };
it.forwardValidate();
return it;
}
const_iterator end(uint_t index = 0) const {
const_iterator it{ SIZE - 1, m_buckets.back().data() + m_buckets.back().size(), this };
return it;
}
std::size_t get_slot(uint_t id) {
return id % SIZE;
}
private:
inline std::pair<std::size_t, std::size_t> findBucketIndex(std::size_t index) {
std::size_t bucket = 0;
std::size_t count = 0;
while (index >= m_buckets[bucket].size() + count) {
count += m_buckets[bucket].size();
++bucket;
}
return { bucket, index - count };
}
};
}
constexpr std::size_t SIZE = 1'000;
constexpr std::size_t INDEXES = 400;
constexpr std::size_t SPACING = 26;
void vectorFindErase(std::vector<int>& values, int value) {
const auto end = values.end();
for (auto it = values.begin(); it != end; ++it) {
if (*it == value) {
values.erase(it);
break;
}
}
}
void vectorEraseSorted(std::vector<int>& values, int value) {
auto it = std::lower_bound(values.begin(), values.end(), value);
if (it != values.end() && !(value < *it)) {
values.erase(it);
}
}
void setErase(std::unordered_set<int>& values, int value) {
values.erase(value);
}
int main() {
std::mt19937 rng;
rng.seed(std::random_device()());
std::vector<int> values(SIZE);
std::generate_n(values.begin(), SIZE, []() {
static int index = 0;
return index++;
});
auto sorted = values;
auto preallocate = values;
auto vnf = values;
std::random_shuffle(vnf.begin(), vnf.end(), [&](auto i) {
return rng() % i;
});
std::vector<int> indexes(INDEXES);
std::generate(indexes.begin(), indexes.end(), [&]() {
return rng() % SIZE;
});
//APPEND VALUES TO BUCKET VECTOR, USE VALUE AS IT'S OWN KEY
BucketVector<int, 23> bucket;
for (auto& value : values) {
bucket.push_back(value, value);
}
Benchmarker<> bench(true);
//NAIVE FIND AND ERASE
for (auto& index : indexes) {
vectorFindErase(vnf, index);
}
std::cout << std::left;
std::cout << std::setw(SPACING) << "Naive Find and Erase: " << bench.stop() << '\n';
//SORTED ERASE
bench.start();
for (auto& index : indexes) {
vectorEraseSorted(sorted, index);
}
std::cout << std::setw(SPACING) << "Sorted erase: " << bench.stop() << '\n';
//PRELLOCATED ERASE
bench.start();
for (auto& index : indexes) {
preallocate[index] = std::numeric_limits<int>::min();
}
std::cout << std::setw(SPACING) << "Prellocated erase: " << bench.stop() << '\n';
//BUCKETVECTOR ERASE
bench.start();
for (auto& index : indexes) {
auto it = bucket.find(index, index);
if (it == bucket.end()) {
continue;
}
bucket.erase(it);
}
std::cout << std::setw(SPACING) << "BucketVector erase: " << bench.stop() << '\n';
//BUCKET SUM/ITERATE
bench.start();
long long bucketSum = 0;
for (std::size_t index = 0; index != 10'000; ++index) {
for (auto& val : bucket) {
bucketSum += val;
}
}
std::cout << std::setw(SPACING) << "Bucket Sum/Iterate: " << bench.stop() << ' ' << bucketSum << '\n';
//PREALLOCATE SUM/ITERATE
bench.start();
long long vfsum = 0;
for (std::size_t index = 0; index != 10'000; ++index) {
for (auto& val : preallocate) {
if (val != std::numeric_limits<int>::min()) {
vfsum += val;
}
}
}
std::cout << std::setw(SPACING) << "Preallocate sum/Iterate: " << bench.stop() << ' ' << vfsum << '\n';
std::cin.get();
return 0;
}
On my machine, I found that the BucketVector was slightly faster to iterate over than a preallocated array when the preallocated array was 50% or more empty with a size of 1000.

O(array-length). Currently, it is justO(1). BTW, I thinkvectorstands forstd::vector, whilearrayis a more general term, thusarrayis a more suitable word, no? – Bullfrogstd::vector. For the main part, if I correctly remember, many tools dealing with slots can can become emply often use a linked list of empty slots to speedup smart allocation. But the goal is different: it is to avoid to compact the array each time something is deleted. – ChlorenchymaMyMap1N, yes, but there is no guarantee. For some instances, I usually iterate it up to 10 times in a time-step (may lead to too often clean-up). For other instances, I usually iterate once every 3 time-steps (may lead to over-size array). By the way, it is a useful idea, thank. – BullfrogMyMap1N. I may need to slow it down by usingmutexthough, because I also do multi-threading (question edited). Or, I may ignore race condition because approximate value is enough. Interesting idea, thank. – BullfrogMyMap1Nthat relates to any certain type (e.g.RigidBody). If aRigidBodyis deleted, how come everyMyMap1Nknow the deletion? I must makerigidBodyX::destroy(){to callrelatedMap1->notifyDelete(rigidBodyX),relatedMap2->notifyDelete(rigidBodyX), ...}. If I don't want to hardcode, I can't find other ways besides registering every relatedMyMap1Ns to listen whenrigidBodyXis deleted. Currently, I register callback using type in template i.e.<WeakPtr_Parent,WeakPtr_Children>automatically. – Bullfrogint(I will edit question). Yes, with the ID technique alone, I can guarantee thatRoom::bodys's length always less than a certain number e.g. 1000, which is still far from efficient. :) – BullfroggetAllChildren(room). There would be a lot of cache miss to iterate 1000 (probably empty) children slots. :P – Bullfrog