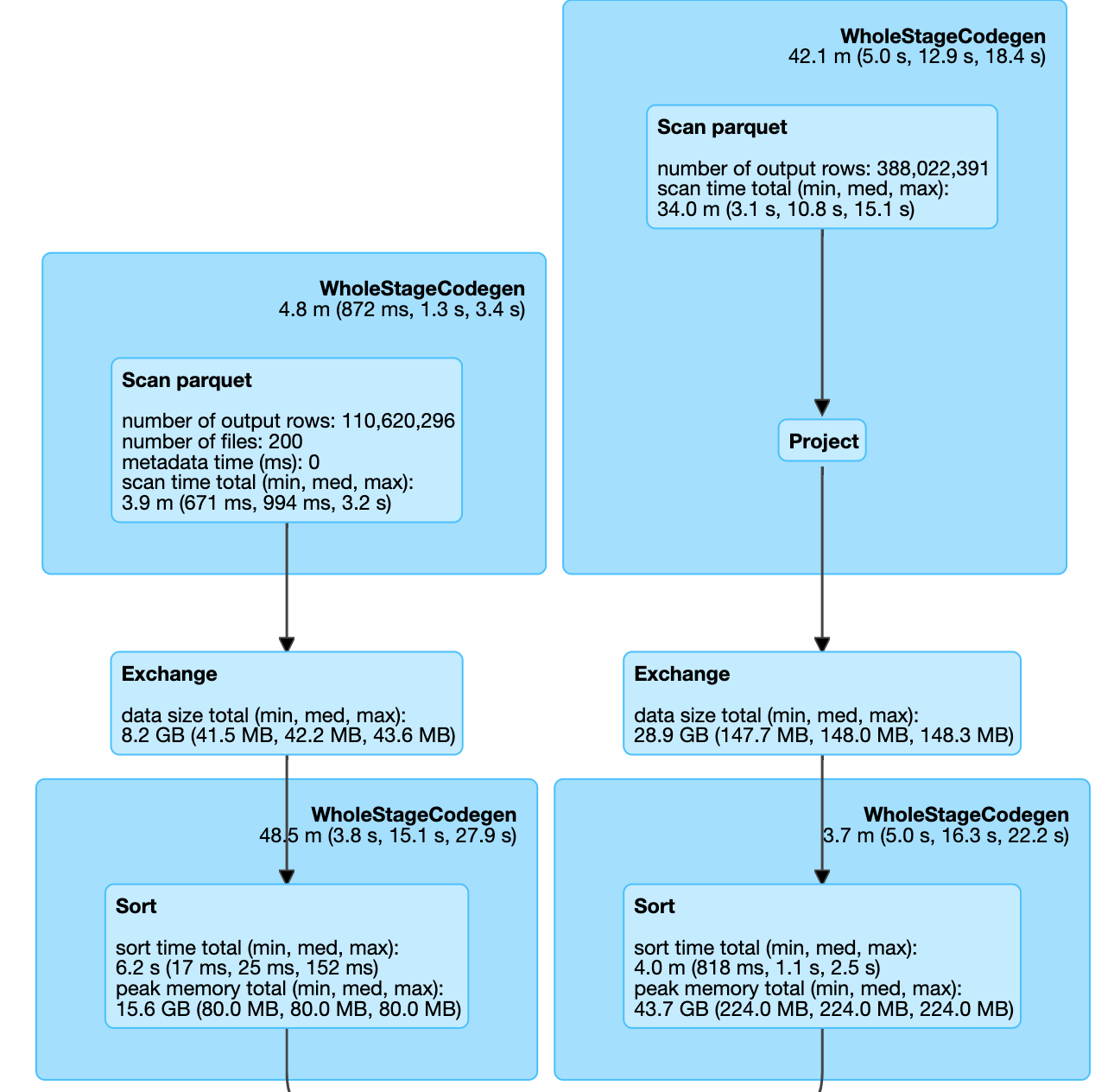
I would like to fully understand the meaning of the information about min/med/max.
for example:
scan time total(min, med, max)
34m(3.1s, 10.8s, 15.1s)
means of all cores, the min scan time is 3.1s and the max is 15.1, the total time accumulated is up to 34 minutes, right?
then for
data size total (min, med, max)
8.2GB(41.5MB, 42.2MB, 43.6MB)
means of all the cores, the max usage is 43.6MB and the min usage is 41.5MB, right?
so the same logic, for the step of Sort at left, 80MB of ram has been used for each core.
Now, the executor has 4 core and 6G RAM, according to the metrix, I think a lot of RAM has been set aside, since each core could use up to around 1G RAM. So I would like to try reducing partition number and force each executor to process more data and reduce shuffle size, do you think theoretically it is possible?