We have a cron job that runs every hour on a backend module and creates tasks. The cron job runs queries on the Cloud SQL database, and the tasks make HTTP calls to other servers and also update the database. Normally they run great, even when thousands of tasks as created, but sometimes it gets "stuck" and there is nothing in the logs that can shed some light on the situation. For example, yesterday we monitored the cron job while it created a few tens of tasks and then it stopped, along with 8 of the tasks that also got stuck in the queue. When it was obvious that nothing was happening we ran the process a few more times and each time completed successfully.
After a day the original task was killed with a DeadlineExceededException and then the 8 other tasks, that were apparently running in the same instance, were killed with the following message: A problem was encountered with the process that handled this request, causing it to exit. This is likely to cause a new process to be used for the next request to your application. If you see this message frequently, you may be throwing exceptions during the initialization of your application. (Error code 104)
Until the processes were killed we saw absolutely no record of them in the logs, and now that we see them there are no log records before the time of the DeadlineExceededException, so we have no idea at what point they got stuck. We suspected that there is some lock in the database, but we see in the following link that there is a 10 minute limit for queries, so that would cause the process to fail much sooner than one day: https://cloud.google.com/appengine/docs/java/cloud-sql/#Java_Size_and_access_limits
Our module's class and scaling configuration is:
<instance-class>B4</instance-class>
<basic-scaling>
<max-instances>11</max-instances>
<idle-timeout>10m</idle-timeout>
</basic-scaling>
The configuration of the queue is:
<rate>5/s</rate>
<max-concurrent-requests>100</max-concurrent-requests>
<mode>push</mode>
<retry-parameters>
<task-retry-limit>5</task-retry-limit>
<min-backoff-seconds>10</min-backoff-seconds>
<max-backoff-seconds>200</max-backoff-seconds>
</retry-parameters>
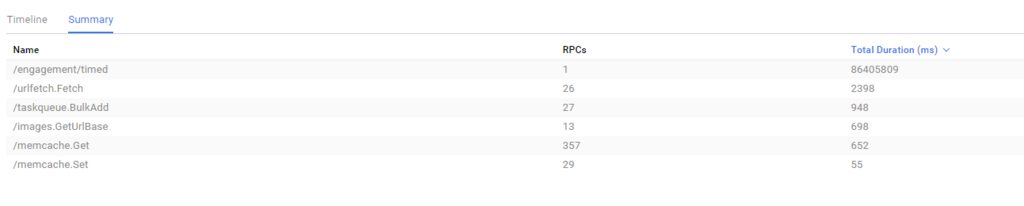
I uploaded some images of the trace data for the cron job: https://i.sstatic.net/1VZar.jpg. This includes the trace summary, and the beginning/ending of the timeline. There is no trace data for the 8 terminated tasks.
{kind=link}
What could be the cause of this and how can we investigate it further?