I am investigating a few slow queries and I need some help reading the data I got.
We have this one particular query which uses an index and runs pretty fast most of the time, however from time to time it runs slow (700ms+), not sure why.
Limit (cost=8.59..8.60 rows=1 width=619) (actual time=5.653..5.654 rows=1 loops=1)
-> Sort (cost=8.59..8.60 rows=1 width=619) (actual time=5.652..5.652 rows=1 loops=1)
Sort Key: is_main DESC, id
Sort Method: quicksort Memory: 25kB
-> Index Scan using index_pictures_on_imageable_id_and_imageable_type on pictures (cost=0.56..8.58
rows=1 width=619) (actual time=3.644..5.587 rows=1 loops=1)
Index Cond: ((imageable_id = 12345) AND ((imageable_type)::text = 'Product'::text))
Filter: (tag = 30)
Rows Removed by Filter: 2
Planning Time: 1.699 ms
Execution Time: 5.764 ms
If I understand that correctly, I would say that almost the entire cost of the query is on index scan, right? which sounds good to me, so why does the same query run pretty slow sometimes?
I started to think that maybe our instance is not being able to keep the entire index in memory, so it is using disk from time to time. That would explain the slow queries. However, that is way over my head. Does that make sense?
That table has around 15 million rows and 5156 MB in size. Index is 1752 MB. BTW, it is a btree index.
Our PostgreSQL is on a "Highly available" Google Cloud SQL instance. It has 2 vCPUs and 7.5 GB of RAM. Our entire database is around 35 GB in size.
CPU consumption almost never goes beyond 40%. It usually settles around 20-30%.
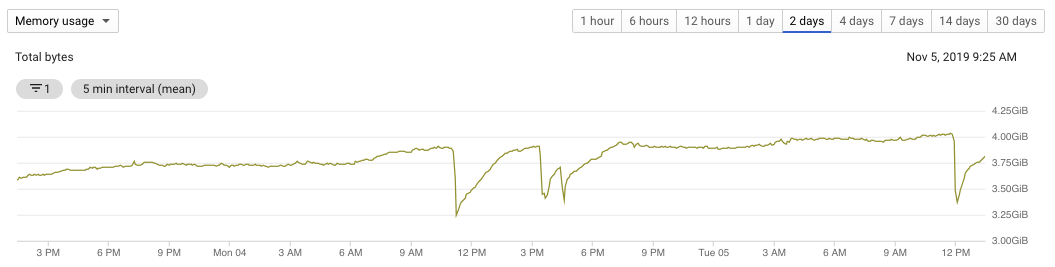
Checking instance memory graph, I noticed that consumption grows until ~4 GB, then it drops down ~700 MB and it starts growing again. That is a repetitive pattern.
In theory, the instance has 7.5 GB of RAM, but I don't know if all of it is supposed to be available for PostgreSQL. Anyway, ~3.5 GB just for OS sounds pretty high, right?
{kind=link}
I read that these configs are important, so throwing them here (Cloud SQL defaults):
shared_buffers | 318976
temp_buffers | 1024
work_mem | 4096
Considering that we have a bunch of other tables and indexes, is it reasonable to assume that if one index alone is 1.7 GB, 7.5 GB for the entire instance is too low?
Is there any way I can assert whether we have a memory issue or not?
I appreciate your help.
5156 MB, index size is1752 MB– StortzEXPLAIN (ANALYZE, BUFFERS), all you can do is guess. Perhaps anACCESS EXCLUSIVElock? Perhaps I/O or CPU overload? Perhaps killed index tuples (do you have big deletes)? – Coffeecolored