I implemented a genetic algorithm to solve an enhanced Traveling Salesman Problem (the weight of the edges changes with the time of the day). Currently I'm evaluating the different parameters of my simulation and I stumbled upon a correlation I can't explain to myself:
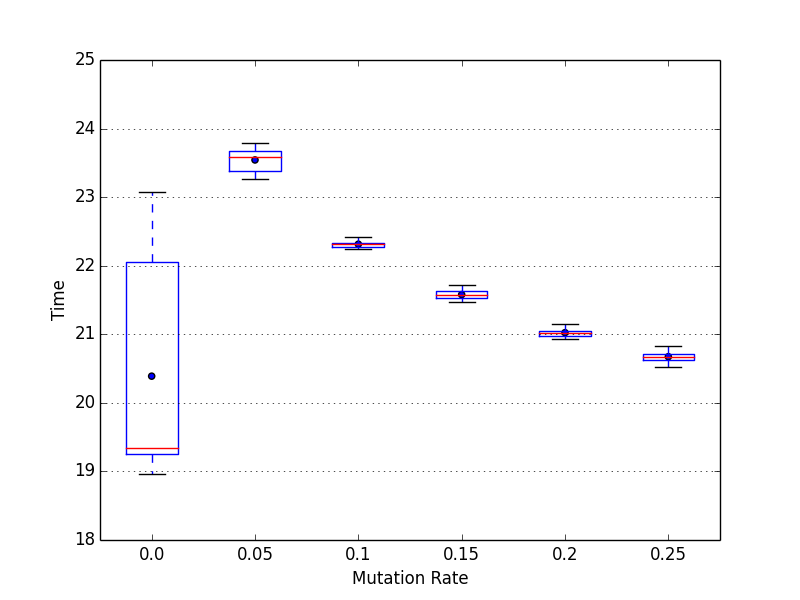
A higher mutation rate leads to a lower run time. Personally I would assume the contrary, since a higher mutation rate produces more operations. (25% Mutation Rate is 12% faster than 5%)
The best results are achieved by a mutation rate of 8% (5% is better than 10% and 25% performs worst (except 0%)) A lower fitness value ist better.
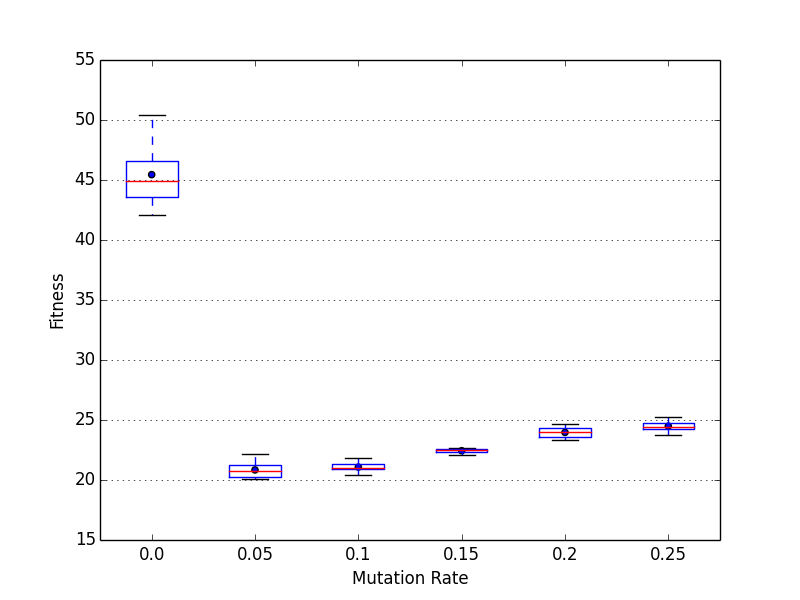
The iteration count is set by the generation parameter which is set to 10.000 in all test cases.
Each test case is executed 10 times.
My implementation (in python) of the mutation looks like this:
def mutate(self,p):
for i in self.inhabitants:
r = random()
if r <= p:
i.mutate()
p is the mutation rate
The mutation looks like this
def mutate(self):
r1 = randint(0,self.locations.size()-1)
r2 = randint(0,self.locations.size()-1)
self.locations.swap(r1,r2)
Why does a higher mutation rate lead to faster execution time?
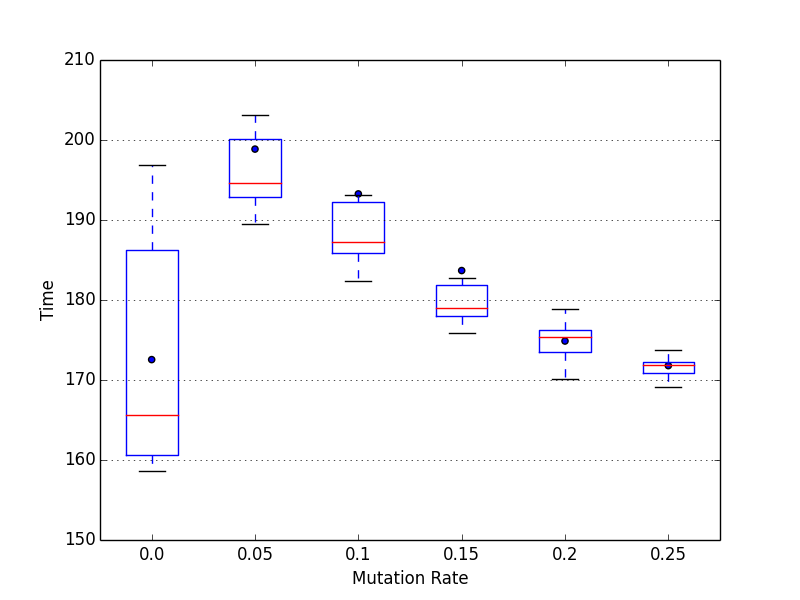
Edit: I actually ran the same tests on my Raspberry Pi (which is 9 times slower) and it results in the same outcome:
start_time = time.time()before I run the simulation and stop it witht = (time.time() - start_time)- that's a gread idea, I'm going to try this as soon as my current tests stop. – Sheepshearing