I will use Airbnb as an example.
When you sign up an Airbnb account, you can become a host by creating a listing. To create a listing, Airbnb UI guides you through the process of creating a new listing in multiple steps:
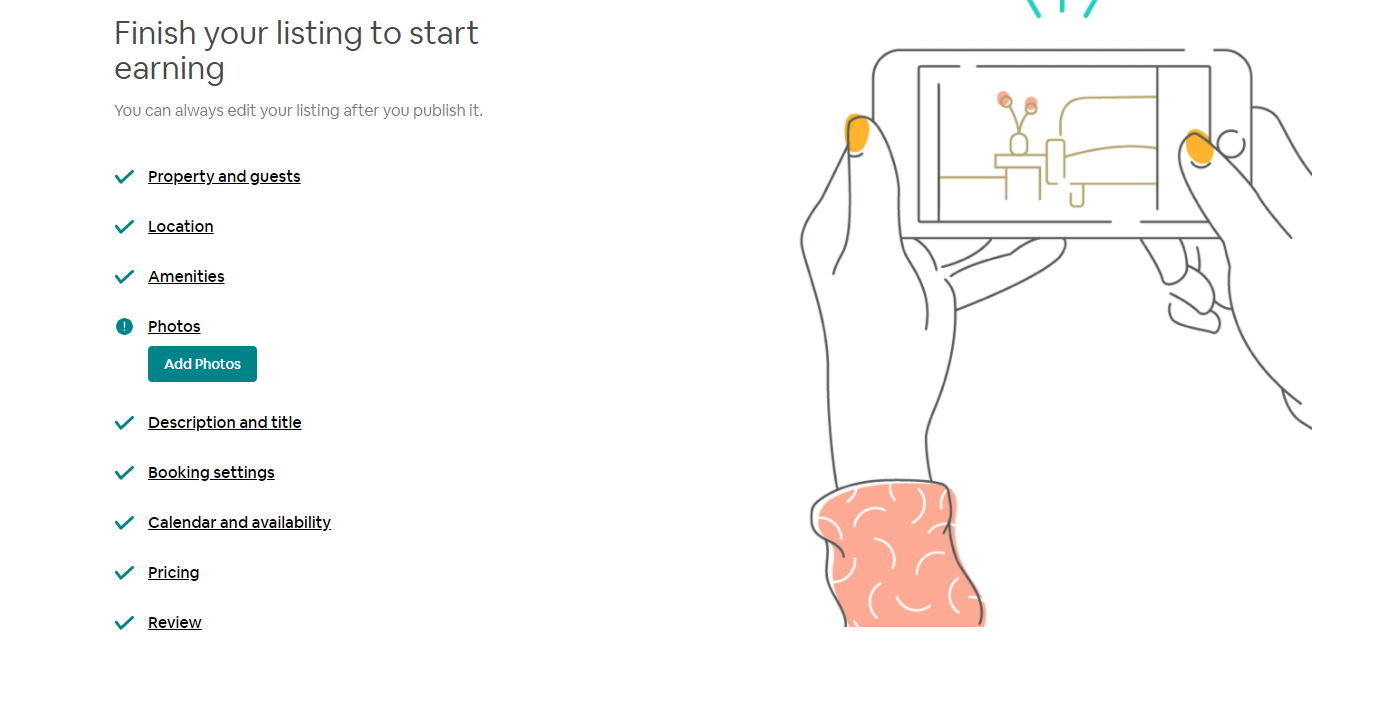
It will also remember your furthest step you've been, so next time when you want to resume the process, it will redirect to where you left.
I've been struggling to decide whether I should put the listing as the aggregate root, and define methods as available steps, or treat each step as their own aggregate roots so that they're small?
Listing as Aggregate Root
public sealed class Listing : AggregateRoot
{
private List<Photo> _photos;
public Host Host { get; private set; }
public PropertyAddress PropertyAddress { get; private set; }
public Geolocation Geolocation { get; private set; }
public Pricing Pricing { get; private set; }
public IReadonlyList Photos => _photos.AsReadOnly();
public ListingStep LastStep { get; private set; }
public ListingStatus Status { get; private set; }
private Listing(Host host, PropertyAddress propertyAddress)
{
this.Host = host;
this.PropertyAddress = propertyAddress;
this.LastStep = ListingStep.GeolocationAdjustment;
this.Status = ListingStatus.Draft;
_photos = new List<Photo>();
}
public static Listing Create(Host host, PropertyAddress propertyAddress)
{
// validations
// ...
return new Listing(host, propertyAddress);
}
public void AdjustLocation(Geolocation newGeolocation)
{
// validations
// ...
if (this.Status != ListingStatus.Draft || this.LastStep < ListingStep.GeolocationAdjustment)
{
throw new InvalidOperationException();
}
this.Geolocation = newGeolocation;
}
...
}
Most of the complex classes in the aggregate root are just value objects, and ListingStatus is just a simple enum:
public enum ListingStatus : int
{
Draft = 1,
Published = 2,
Unlisted = 3,
Deleted = 4
}
But ListingStep could be an enumeration class that stores the next step the current step can advance:
using Ardalis.SmartEnum;
public abstract class ListingStep : SmartEnum<ListingStep>
{
public static readonly ListingStep GeolocationAdjustment = new GeolocationAdjustmentStep();
public static readonly ListingStep Amenities = new AmenitiesStep();
...
private ListingStep(string name, int value) : base(name, value) { }
public abstract ListingStep Next();
private sealed class GeolocationAdjustmentStep : ListingStep
{
public GeolocationAdjustmentStep() :base("Geolocation Adjustment", 1) { }
public override ListingStep Next()
{
return ListingStep.Amenities;
}
}
private sealed class AmenitiesStep : ListingStep
{
public AmenitiesStep () :base("Amenities", 2) { }
public override ListingStep Next()
{
return ListingStep.Photos;
}
}
...
}
The benefits of having everything in the listing aggregate root is that everything would be ensured to have transaction consistency. And the steps are defined as one of the domain concerns.
The drawback is that the aggregate root is huge. On each step, in order to call the listing actions, you have to load up the listing aggregate root, which contains everything.
To me, it sounds like except the geolocation adjustment might depend on the property address, other steps don't depend on each other. For example, the title and the description of the listing doesn't care what photos you upload.
So I was thinking whether I can treat each step as their own aggregate roots?
Each step as own Aggregate Root
public sealed class Listing : AggregateRoot
{
public Host Host { get; private set; }
public PropertyAddress PropertyAddress { get; private set; }
private Listing(Host host, PropertyAddress propertyAddress)
{
this.Host = host;
this.PropertyAddress = propertyAddress;
}
public static Listing Create(Host host, PropertyAddress propertyAddress)
{
// Validations
// ...
return new Listing(host, propertyAddress);
}
}
public sealed class ListingGeolocation : AggregateRoot
{
public Guid ListingId { get; private set; }
public Geolocation Geolocation { get; private set; }
private ListingGeolocation(Guid listingId, Geolocation geolocation)
{
this.ListingId = listingId;
this.Geolocation = geolocation;
}
public static ListingGeolocation Create(Guid listingId, Geolocation geolocation)
{
// Validations
// ...
return new ListingGeolocation(listingId, geolocation);
}
}
...
The benefits of having each step as own aggregate root is that it makes aggregate roots small (To some extends I even feel like they're too small!) so when they're persisted back to data storage, the performance should be quicker.
The drawback is that I lost the transactional consistency of the listing aggregate. For example, the listing geolocation aggregate only references the listing by the Id. I don't know if I should put a listing value object there instead so that I can more information useful in the context, like the last step, listing status, etc.
Close as Opinion-based?
I can't find any example online where it shows how to model this wizard-like style in DDD. Also most examples I've found about splitting a huge aggregate roots into multiple smaller ones are about one-to-many relationships, but my example here is mostly about one-to-one relationship (except photos probably).
I think my question would not be opinion-based, because
- There are only finite ways to go about modeling aggregates in DDD
- I've introduced a concrete business model airbnb, as an example.
- I've listed 2 approaches I've been thinking.
You can suggest me which approach you would take and why, or other approaches different from the two I listed and the reasons.