I am trying to implement the Youtube's Thumbnail Preview feature for my Simple Video Player. Here's the Snap for it :
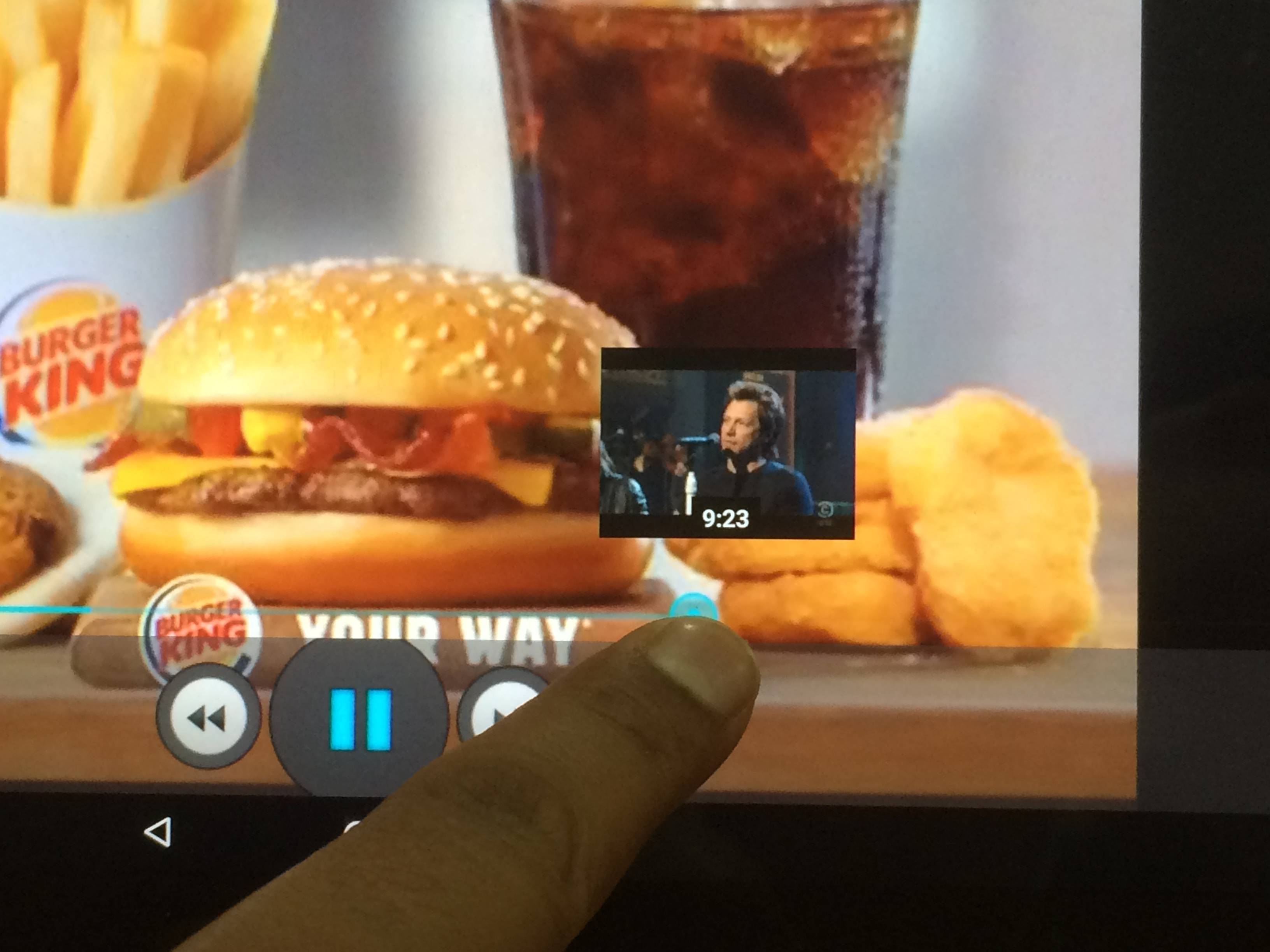
Good thing is : It is working smoothly once the Player fetch all the thumbnails previews from a HTTP server.
Bad thing is : Fetching of all Thumbnail previews is taking huge time (20-30 seconds). (For a video (.mp4 file) of 14 minutes (~110 MB), roughly 550 thumbnails previews (160x120) are there)
What I am doing is : When the user will start playing the video, I will make "total_thumbnails" HTTP request to Server to get all of them.
Also-Note :
- I will do the multiple HTTP request thingy in an Async Task.
- I will not do it in the fashion, make a request, wait until download complete and then make another request.
- I will make "total_thumbnails" HTTP requests blindly, so all the request get queued in the pipeline and later receiving responses in parallel.
Extra Details : A HTTP (lighttpd) Server will be running, from where my player will fetch all the thumbnails as soon the user select a video.mp4 to play from the list. Also, the same server will be used by the player to fetch video.mp4 using HTTP streaming.
Problem is : When I will start playing the video, and then I quickly do seeking, I end up seeing this (the white thumbnail is the default one, when the thumbnails mapped to that time is not yet fetch from Server) :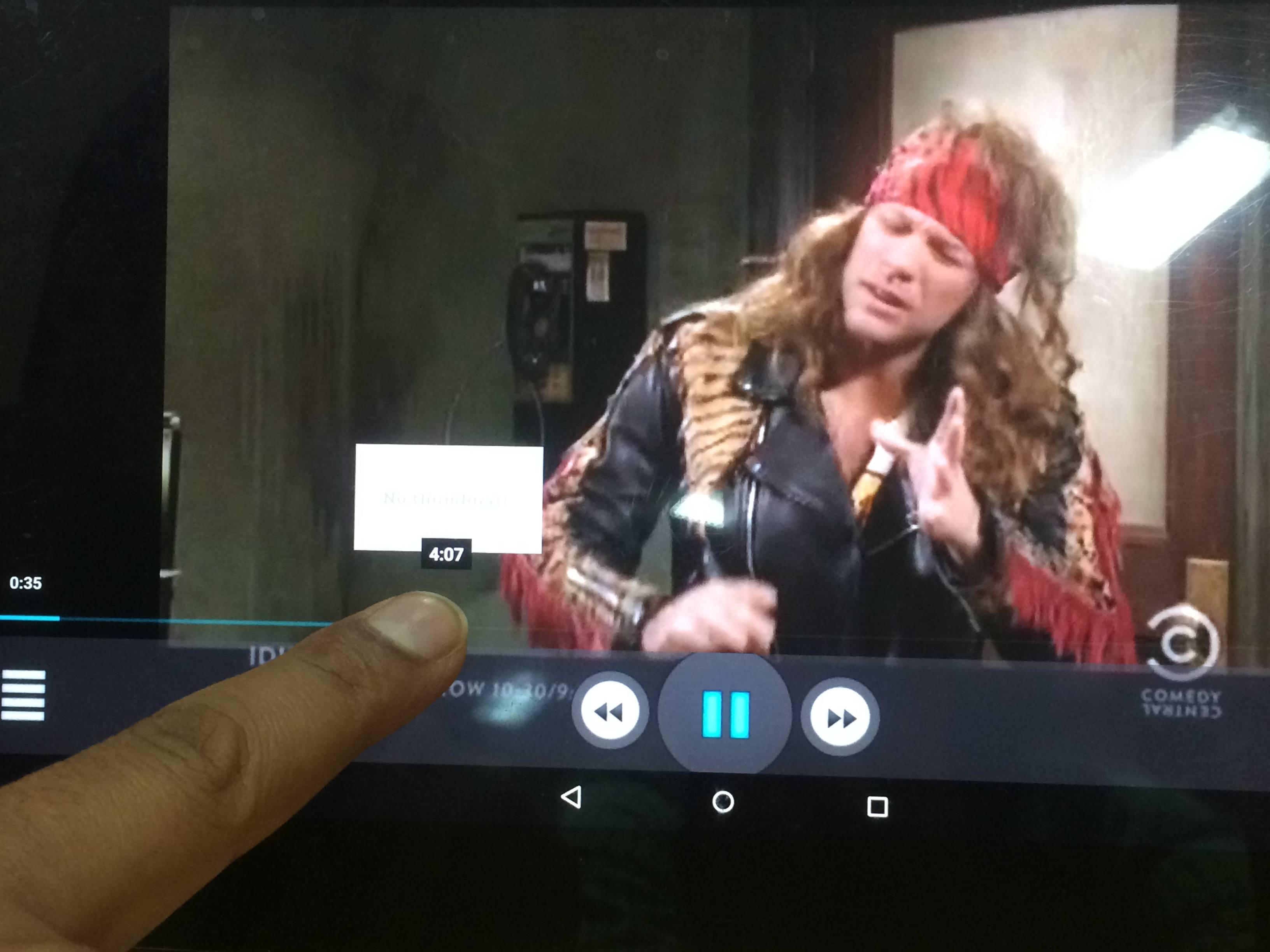
Question is : How efficiently can I fetch all (or some) thumbnail previews so that the User (most of the time) will get the experience of right timely mapped thumbnail?
I have seen youtube's video as soon as the video start (which is quick), the player is able to show all the timely right thumbnails (No matter you drag the thumb to the last minute or hover over the bar's last minutes, almost every time you will see the rightly mapped thumbnail).
Are they downloading all the thumbnails at the same time or downloading the compressed thumbnail previews series or some other intelligent stuff is happening out there?
Has anyone has worked out on this?
{kind=link}