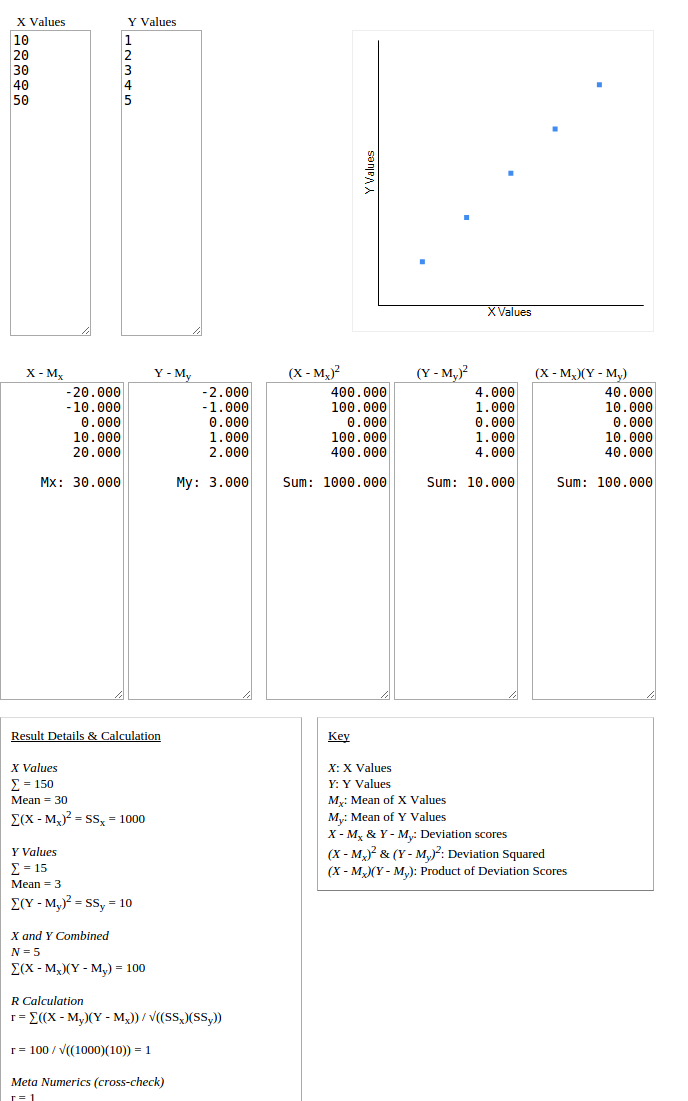
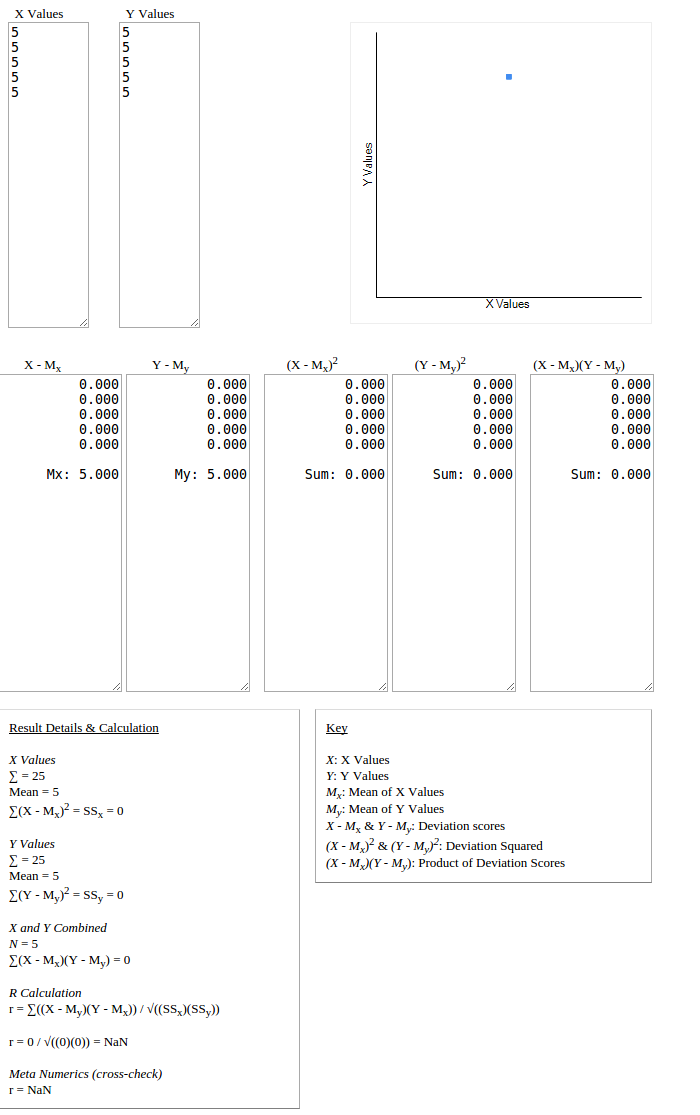
Consider the following examples of the Pearson correlation coefficient on sets of film ratings by users A and B:
A = [2,4,4,4,4]
B = [5,4,4,4,4]
pearson(A,B) = -1
A = [5,5,5,5,5]
B = [5,5,5,5,5]
pearson(A,B) = NaN
Pearson correlation seems widely used for calculating the similarity between two sets in collaborative filtering. However the sets above show high (even perfect) similarity, yet the outputs suggest the sets are negatively correlated (or an error is encountered due to div by zero).
I initially thought it was an issue in my implementation, but I've since validated it against a few online calculators.
If the outputs are correct, why is Pearson correlation considered a good choice for this application?