I'm new to Kafka, and our team is investigating patterns for inter-service communication.
The goal
We have two services, P (Producer) and C (Consumer). P is the source of truth for a set of data that C needs. When C starts up it needs to load all of the current data from P into its cache, and then subscribe to change notifications. (In other words, we want to synchronize data between the services.)
The total amount of data is relatively low, and changes are infrequent. A brief delay in synchronization is acceptable (eventual consistency).
We want to decouple the services so that P and C do not need to know about each other.
The proposal
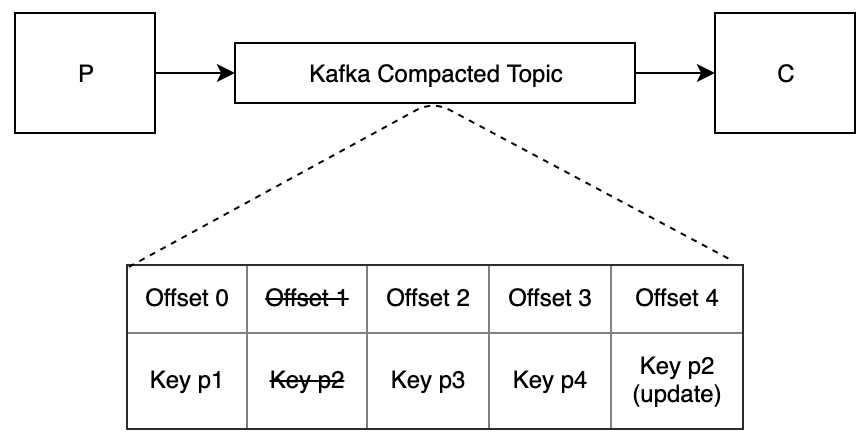
When P starts up, it publishes all of its data to a Kafka topic that has log compaction enabled. Each message is an aggregate with a key of its ID.
When C starts up, it reads all of the messages from the beginning of the topic and populates its cache. It then keeps reading from its offset to be notified of updates.
When P updates its data, it publishes a message for the aggregate that changed. (This message has the same schema as the original messages.)
When C receives a new message, it updates the corresponding data in its cache.
Constraints
We are using the Confluent REST Proxy to communicate with Kafka.
The issue
When C starts up, how does it know when it's read all of the messages from the topic so that it can safely start processing?
It's acceptable if C does not immediately notice a message that P sent a second ago. It's not acceptable if C starts processing before consuming a message that P sent an hour ago. Note that we don't know when updates to P's data will occur.
We do not want C to have to wait for the REST Proxy's poll interval after consuming each message.