I experience unexpected performance issues when writing to BigQuery with streaming inserts and Python SDK 2.23.
Without the write step the pipeline runs on one worker with ~20-30% CPU. Adding the BigQuery step the pipeline scales up to 6 workers all on 70-90% CPU.
I am pretty new to Dataflow and Beam and probably this behaviour is normal or I am doing something wrong but it seems to me that using 6 machines to write 250 rows per second to BigQuery is a bit heavy. I'm wondering how it is even possible to reach the insertion quota of 100K rows per second.
My pipeline looks like this:
p
| "Read from PubSub" >> beam.io.ReadFromPubSub(subscription=options.pubsub_subscription) # ~40/s
| "Split messages" >> beam.FlatMap(split_messages) # ~ 400/s
| "Prepare message for BigQuery" >> beam.Map(prepare_row)
| "Filter known message types" >> beam.Filter(filter_message_types) # ~ 250/s
| "Write to BigQuery" >> beam.io.WriteToBigQuery(
table=options.table_spec_position,
schema=table_schema,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
create_disposition=beam.io.BigQueryDisposition.CREATE_NEVER,
additional_bq_parameters=additional_bq_parameters,
)
The pipeline runs with these option although I experienced a similar behaviour without using streaming engine.
--enable_streaming_engine \
--autoscaling_algorithm=THROUGHPUT_BASED \
--max_num_workers=15 \
--machine_type=n1-standard-2 \
--disk_size_gb=30 \
Screenshot of metrics:

My Question is if this behaviour is normal or is there anything I can do to reduce the number of required workers for this pipeline. Thanks!
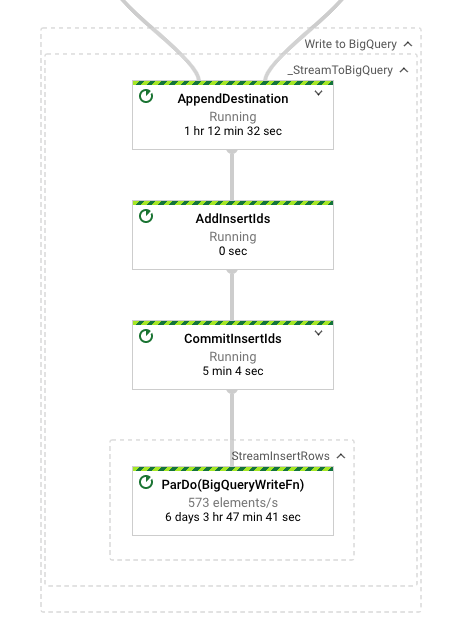
Update: Here is an image of the last step of the dataflow graph with wall times. (taken after the job was running for 1h). All the other steps before have very low wall times of only a few seconds.