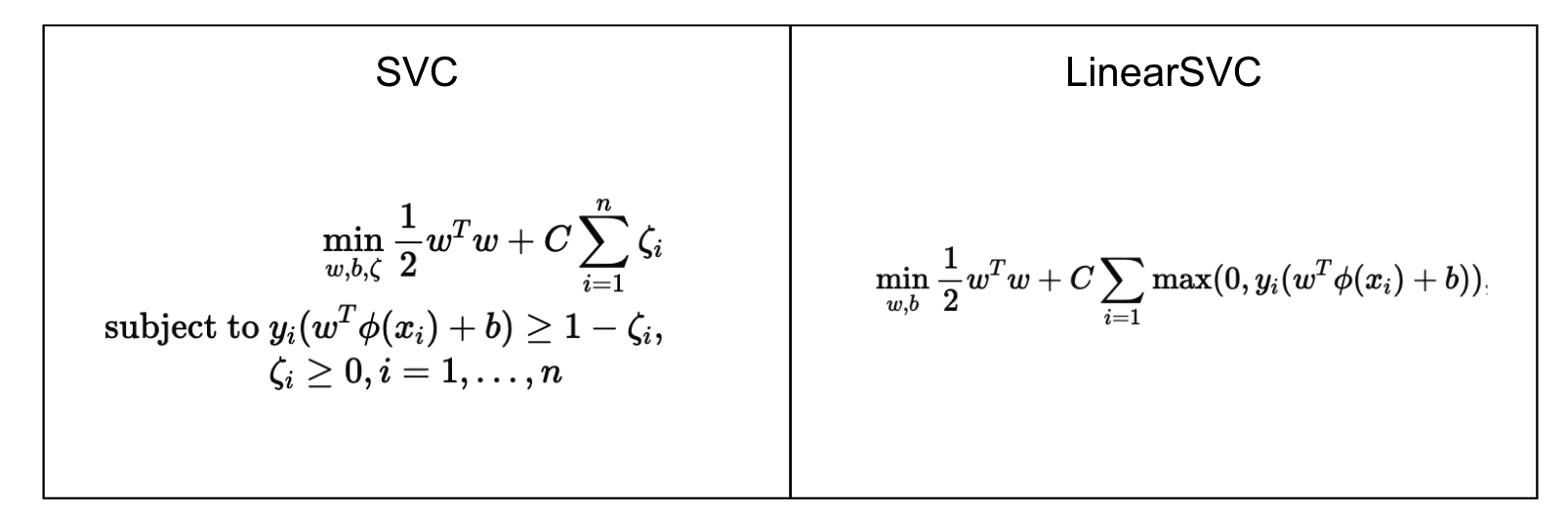SVC is a wrapper of LIBSVM library, while LinearSVC is a wrapper of LIBLINEAR
LinearSVC is generally faster then SVC and can work with much larger datasets, but it can only use linear kernel, hence its name. So the difference lies not in the formulation but in the implementation approach.
Quoting LIBLINEAR FAQ:
When to use LIBLINEAR but not LIBSVM
There are some large data for which with/without nonlinear mappings gives similar performances.
Without using kernels, one can quickly train a much larger set via a linear classifier.
Document classification is one such application.
In the following example (20,242 instances and 47,236 features; available on LIBSVM data sets),
the cross-validation time is significantly reduced by using LIBLINEAR:
% time libsvm-2.85/svm-train -c 4 -t 0 -e 0.1 -m 800 -v 5 rcv1_train.binary
Cross Validation Accuracy = 96.8136%
345.569s
% time liblinear-1.21/train -c 4 -e 0.1 -v 5 rcv1_train.binary
Cross Validation Accuracy = 97.0161%
2.944s
Warning:While LIBLINEAR's default solver is very fast for document classification, it may be slow in other situations. See Appendix C of our SVM guide about using other solvers in LIBLINEAR.
Warning:If you are a beginner and your data sets are not large, you should consider LIBSVM first.