I sat out determined to give this a go with using as much pandas as possible. I couldn't figure out a better way than @BoppreH to actually implement the business logic of the peak determination.
I create a configurable filter to be applied to the rows of the DataFrame with a decorator for state storage:
def min_percent_change_filter(min_change_percent=0.05):
peaks = []
get_change = lambda a, b: (b - a) / a
def add_entry(row):
"""By @BoppreH, with slight modifications
Update list of peaks with one new entry."""
if len(peaks) >= 2 and (row["data"] > peaks[-1]["data"]) == (
peaks[-1]["data"] > peaks[-2]["data"]
):
# Continue movement of same direction by replacing last peak.
peaks[-1] = row.copy()
return peaks
elif (
not peaks
or abs(get_change(peaks[-1]["data"], row["data"])) >= min_change_percent
):
# New peak is above minimum threshold.
peaks.append(row.copy())
return peaks
return peaks
return add_entry
The pandas part requires quite some manipulation to get the data into the right shape. After it's in the right shape, we apply the filter across rows. Finally we put the DataFrame in the desired output format:
import pandas as pd
def pandas_approach(data, min_pct_change):
df = pd.DataFrame(data)
df["open_time"] = pd.to_datetime(df["open_time"])
# Respect termporal aspect, create new columns first and second
# set them to the respective value depending on whether we're
# moving down or up
df["first"] = df["low"].where(df["open"] <= df["close"], df["high"])
df["second"] = df["high"].where(df["open"] <= df["close"], df["low"])
# Create a new representation of the data, by stacking first and second
# on the index, then sorting by 'open_time' and whether it came first
# or second (Note: assert 'first' < 'second')
stacked_representation = (
df.set_index("open_time")[["first", "second"]]
.stack()
.reset_index()
.sort_values(["open_time", "level_1"])[["open_time", 0]]
)
stacked_representation.columns = ["open_time", "data"]
# Now we can go to work with our filter
results = pd.DataFrame(
stacked_representation.apply(min_percent_change_filter(min_pct_change), axis=1)[
0
]
)
# We reshape /rename/reorder our data to fit the desired output format
results["begin"] = results["data"].shift()
results["begin_date"] = results["open_time"].shift()
results = results.dropna()[["begin_date", "begin", "open_time", "data"]]
results.columns = ["begin_date", "begin", "end_date", "end"]
# Lastly add the pct change
results["pct_change"] = (results.end - results.begin) / results.begin
# This returns the styler for output formatting purposes, but you can return the
# DataFrame instead by commenting/deleting it
def format_datetime(dt):
return pd.to_datetime(dt).strftime("%Y-%m-%d")
def price_formatter(value):
return "{:.4f}".format(value) if abs(value) < 10000 else "{:.0f}".format(value)
return results.style.format(
{
"pct_change": "{:,.2%}".format,
"begin_date": format_datetime,
"end_date": format_datetime,
"begin": price_formatter,
"end": price_formatter,
}
)
Output for the first example::
import pandas as pd
data = {
"open_time": ["2023-07-02", "2023-07-03", "2023-07-04", "2023-07-05", "2023-07-06"],
"open": [0.12800000, 0.12360000, 0.12830000, 0.12410000, 0.11990000],
"high": [0.12800000, 0.13050000, 0.12830000, 0.12530000, 0.12270000],
"low": [0.12090000, 0.12220000, 0.12320000, 0.11800000, 0.11470000],
"close": [0.12390000, 0.12830000, 0.12410000, 0.11980000, 0.11500000],
}
pandas_approach(data,0.05)
begin_date begin end_date end pct_change
1 2023-07-02 0.1280 2023-07-02 0.1209 -5.55%
3 2023-07-02 0.1209 2023-07-03 0.1305 7.94%
9 2023-07-03 0.1305 2023-07-06 0.1147 -12.11%
Output for the second example:
data_2 = {
"open_time": ["2022-02-25", "2022-02-26", "2022-02-27", "2022-02-28", "2022-03-01"],
"open": [38340.4200, 39237.0700, 39138.1100, 37714.4200, 43176.4100],
"high": [39699.0000, 40300.0000, 39881.7700, 44200.0000, 44968.1300],
"low": [38038.4600, 38600.4600, 37027.5500, 37468.2800, 42838.6800],
"close": [39237.0600, 39138.1100, 37714.4300, 43181.2700, 44434.0900],
}
pandas_approach(data_2, 0.03)
begin_date begin end_date end pct_change
2 2022-02-25 38038 2022-02-26 40300 5.95%
3 2022-02-26 40300 2022-02-26 38600 -4.22%
4 2022-02-26 38600 2022-02-27 39882 3.32%
5 2022-02-27 39882 2022-02-27 37028 -7.16%
7 2022-02-27 37028 2022-02-28 44200 19.37%
8 2022-02-28 44200 2022-03-01 42839 -3.08%
9 2022-03-01 42839 2022-03-01 44968 4.97%
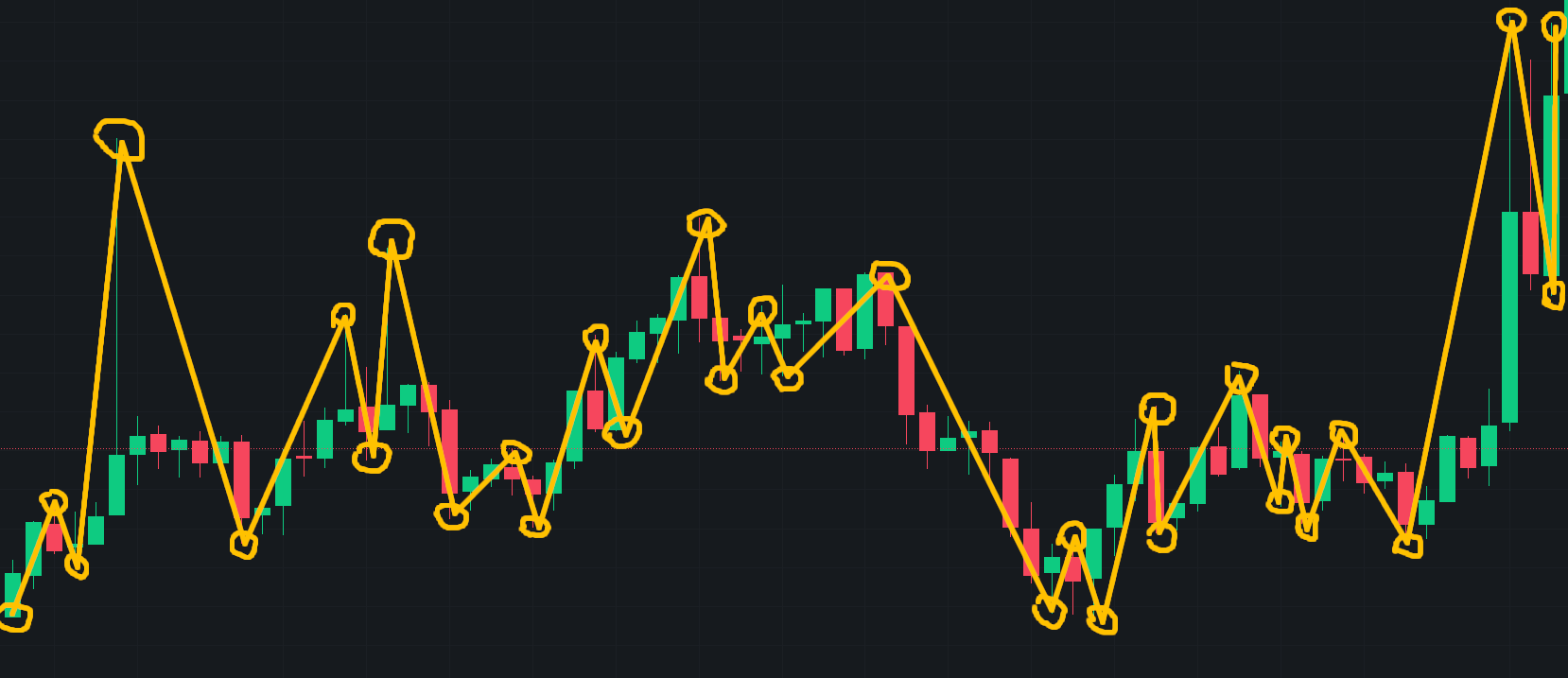
val2,val3, etc. are. Nor do I understand your results; you skip from 7/3 to 7/6, but the data has 7/4 and 7/5 in it. – Porkpiehighentry used? Isn't it a problem that thelowvalue might have come before thehigh? – Mancy