I am new to Python and the world of NLP. The recent announcement of Google's Syntaxnet intrigued me. However I am having a lot of trouble understanding documentation around both syntaxnet and related tools (nltk, etc.)
My goal: given an input such as "Wilbur kicked the ball" I would like to extract the root verb (kicked) and the object it pertains to "the ball".
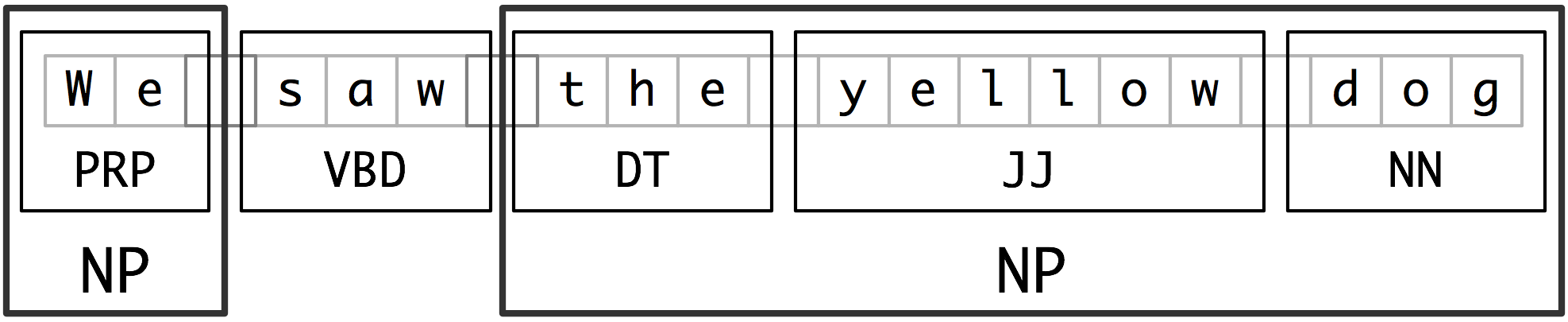
I stumbled across "spacy.io" and this visualization seems to encapsulate what I am trying to accomplish: POS tag a string, and load it into some sort of tree structure so that I can start at the root verb and traverse the sentence.
I played around with the syntaxnet/demo.sh, and as suggested in this thread commented out the last couple lines to get conll output.
I then loaded this input in a python script (kludged together myself, probably not correct):
import nltk
from nltk.corpus import ConllCorpusReader
columntypes = ['ignore', 'words', 'ignore', 'ignore', 'pos']
corp = ConllCorpusReader('/Users/dgourlay/development/nlp','input.conll', columntypes)
I see that I have access to corp.tagged_words(), but no relationship between the words. Now I am stuck! How can I load this corpus into a tree type structure?
Any help is much appreciated!
{kind=link}