Goal: create Elasticsearch index aimed to be loaded with 10 million simple documents. Each document is basically "Elastisearch id", "some company id" and "name". Provide search-as-suer-type feature.
I could created successfully an index and an analyzer either straight from Postman (curl or any other tool not relying on Spring Data) or during Spring boot initialization. Nevertheless, when I try to use the analizer it seems it is ignored for the one created straight from Postman.
So my main question is: is Springdata adding some setting I am missing when I try straight from posting the json stting? A secondary question is: is there someway to enable Springdata to print the commands auto-generated and executed (kind of similar approach with Hibernate whihc allows you to see the commands printed)? If so, I can visually debug and check what is different.
This is the way creting Index and Analyzer from Springboot/Spring-Data.
main method to boot
@EnableElasticsearchRepositories
@SpringBootApplication
public class SearchApplication {
public static void main(String[] args) {
SpringApplication.run(SearchApplication.class, args);
}
}
my model
@Document(indexName = "correntistas")
@Setting(settingPath = "data/es-config/elastic-setting.json")
@Getter
@Setter
public class Correntista {
@Id
private String id;
private String conta;
private String sobrenome;
@Field(type = FieldType.Text, analyzer = "autocomplete_index", searchAnalyzer = "autocomplete_search")
private String nome;
}
src/main/resources/data/es-config/elastic-setting.json *** NOTE THIS IS EXACTLY THE SAME SETTING I AM POSTING FROM POSTMAN
{
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete_search": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase"
]
},
"autocomplete_index": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
}
Checking if it was created succesfully I see:
get http://localhost:9200/correntistas/_settings
{
"correntistas": {
"settings": {
"index": {
"number_of_shards": "5",
"provided_name": "correntistas",
"creation_date": "1586615323459",
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "20"
}
},
"analyzer": {
"autocomplete_index": {
"filter": [
"lowercase",
"autocomplete_filter"
],
"type": "custom",
"tokenizer": "standard"
},
"autocomplete_search": {
"filter": [
"lowercase"
],
"type": "custom",
"tokenizer": "standard"
}
}
},
"number_of_replicas": "1",
"uuid": "xtN-NOX3RQWJjeRdyC8CVA",
"version": {
"created": "6080499"
}
}
}
}
}
So far so good.
Now I delete the index with curl -XDELETE localhost:9200/correntistas and I will do the same idea but creating the index and analyzer at once from Postman:
put http://localhost:9200/correntistas with exact same analyzer posted above:
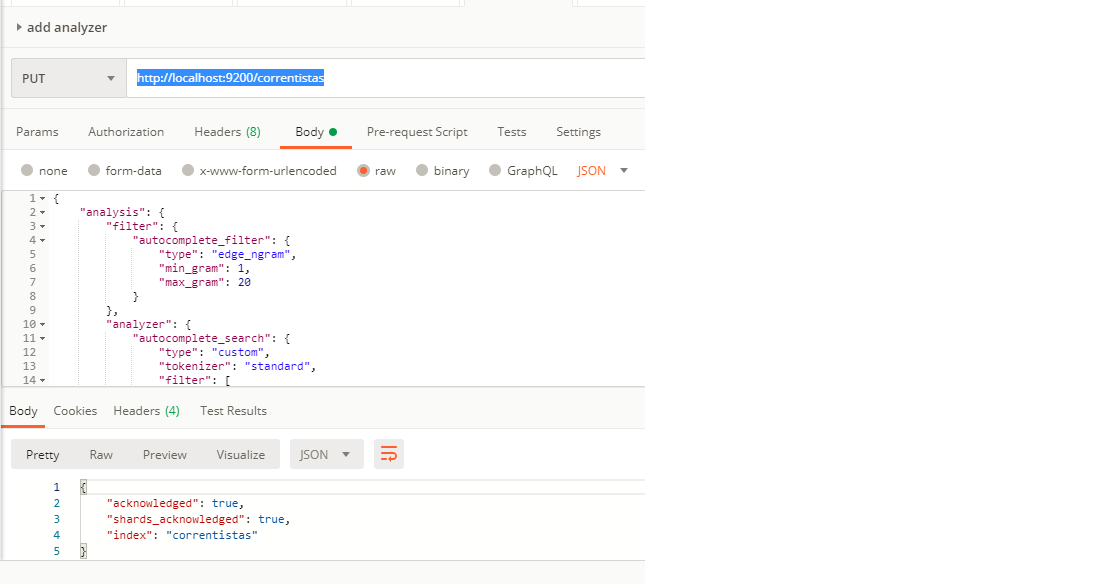
Then if I check I the settings I see exact the same result as it was created above from Spring-Data.
Am I missing some extra step that Spring-Data is giving by free and hiding from eyes?
To sum up, when created from Spring-data I see searching with few letters working but when Icreated from postman it simply retrieve data when I search with whole word.
*** Thanks to so friendly and smart help from Opster Elasticsearch Ninja I can add here an extra trick I had learned when posting from Postman (somehow some header enabled in my Postman was crashing with "... Root mapping definition has unsupported parameters... mapper_parsing_exception..." while trying the solution answered bellow. I guess it can be usefull to add here for future readers.