I'm tried to implement basic GAN in Keras, based on this implementation.
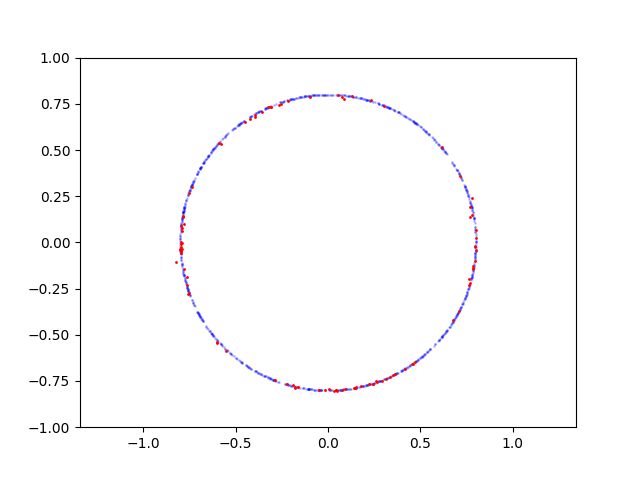
If I sample points on parabola GAN is converges and able to produce samples from this distribution, but if for example I sample points on circle it fails. I wonder why it's hard for GAN? How it can be fixed?
Here is learning process for parabola:

Here is learning process for circle:
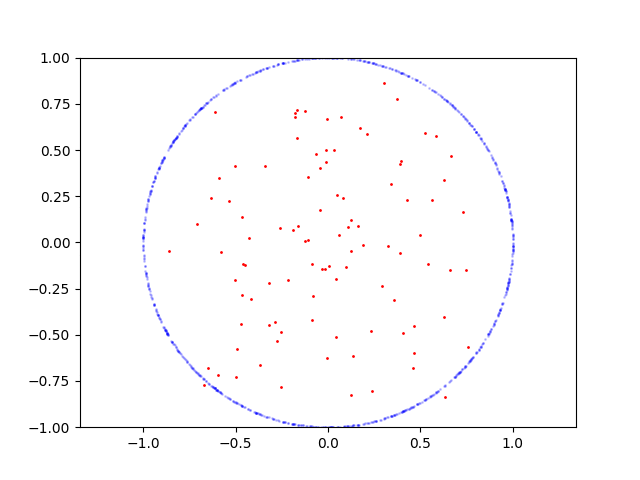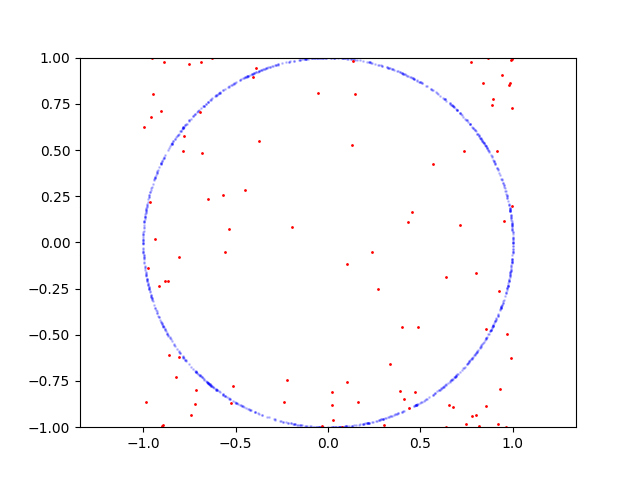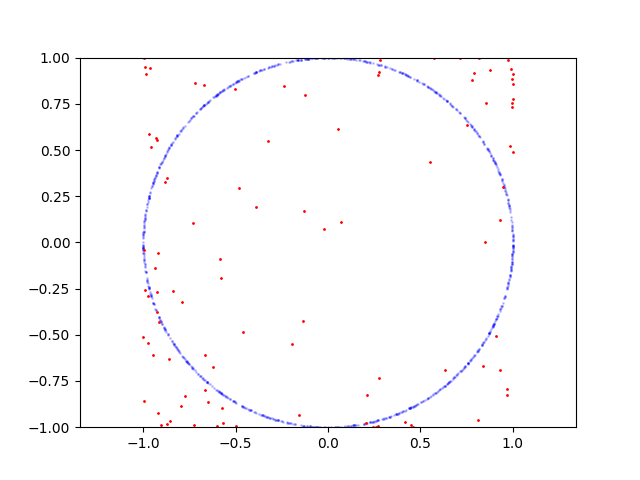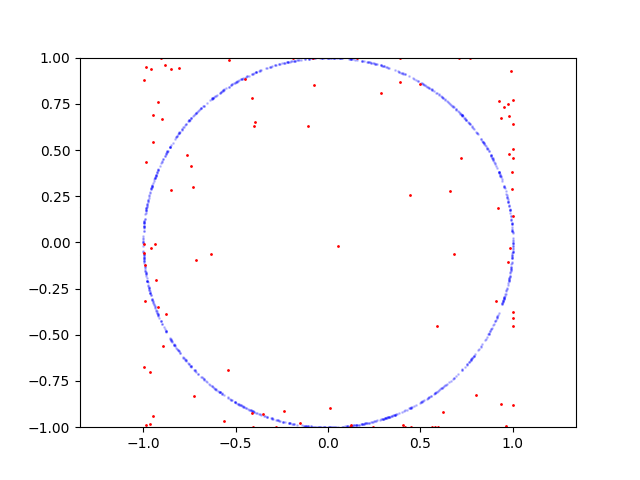
Here is the code to reproduce:
from __future__ import print_function, division
import warnings
warnings.filterwarnings('ignore')
import os
import shutil
from datetime import datetime
from keras.layers import Input, Dense
from keras.layers.advanced_activations import LeakyReLU
from keras.models import Sequential, Model
from keras.optimizers import Adam
from sklearn import datasets
import numpy as np
import tensorflow as tf
from tqdm import tqdm
import matplotlib.pyplot as plt
import cv2
# Derived from original code https://github.com/eriklindernoren/Keras-GAN/blob/master/gan/gan.py
def print_env_info():
print('-' * 60)
import keras
print('keras.__version__', keras.__version__)
print('-' * 60)
import tensorflow as tf
print('tf.__version__', tf.__version__)
print('-' * 60)
class GAN():
def __init__(self):
self.latent_dim = 128
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build the generator
self.generator = self.build_generator()
# The generator takes noise as input and generates imgs
z = Input(shape=(self.latent_dim,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The discriminator takes generated images as input and determines validity
validity = self.discriminator(img)
# The combined model (stacked generator and discriminator)
# Trains the generator to fool the discriminator
self.combined = Model(z, validity)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
# Tensorboard writer
log_dir = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
self.writer = tf.summary.FileWriter(log_dir)
def build_generator(self):
model = Sequential()
model.add(Dense(64, input_dim=self.latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(128, input_dim=2))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(2, activation='tanh'))
model.summary()
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
model = Sequential()
model.add(Dense(64, input_dim=2))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(128, input_dim=2))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=(2, ))
validity = model(img)
return Model(img, validity)
def generate_dataset(self, n_samples=10000):
# # V1: y = x^2
x = np.random.uniform(-1, 1, size=n_samples)
y = x ** 2
data = np.stack([x, y], axis=1)
# V2: x ^ 2 + y ^ 2 = 1
# angle = np.random.uniform(0, 1, size=n_samples) * (np.pi * 2)
# x = np.cos(angle)
# y = np.sin(angle)
# data = np.stack([x, y], axis=1)
# V3: swiss roll
# data, _ = datasets.make_swiss_roll(n_samples=n_samples, noise=0.0, random_state=0)
# data = np.stack([data[:, 0], data[:, 2]], axis=1)
# data = data - np.min(data, axis=0)
# data = data / np.max(data, axis=0)
# data = 2 * data - 1.0
# # V4:
# data, _ = datasets.make_moons(n_samples=n_samples, shuffle=False, noise=None, random_state=0)
# data = data - np.min(data, axis=0)
# data = data / np.max(data, axis=0)
# data = 2 * data - 1.0
return data
def summary_image(self, tensor):
import io
from PIL import Image
tensor = tensor.astype(np.uint8)
height, width, channel = tensor.shape
image = Image.fromarray(tensor)
output = io.BytesIO()
image.save(output, format='PNG')
image_string = output.getvalue()
output.close()
return tf.Summary.Image(height=height,
width=width,
colorspace=channel,
encoded_image_string=image_string)
def get_visualization(self, epoch):
def generate_fake_data(n_samples):
noise = np.random.normal(0, 1, (n_samples, self.latent_dim))
X_hat = self.generator.predict(noise)
x = X_hat[:, 0]
y = X_hat[:, 1]
return x, y
def save_figure():
x_fake, y_fake = generate_fake_data(n_samples=100)
data = self.generate_dataset(n_samples=1000)
x_real, y_real = data[:, 0], data[:, 1]
axes = plt.gca()
axes.set_xlim([-1, 1])
axes.set_ylim([-1, 1])
axes.set_aspect('equal', 'datalim')
plt.scatter(x_real, y_real, s=1, color='b', alpha=0.2)
plt.scatter(x_fake, y_fake, s=1, color='r')
plt.savefig(f'images/{epoch}.png')
plt.close()
save_figure()
image = cv2.imread(f'images/{epoch}.png')
image = self.summary_image(image)
return image
def train(self, epochs, batch_size, sample_interval):
# Load the dataset
X_train = self.generate_dataset()
print('X_train.shape', X_train.shape)
# Adversarial ground truths
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in tqdm(range(epochs), total=epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random batch of images
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Generate a batch of new images
gen_imgs = self.generator.predict(noise)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
# Train the generator (to have the discriminator label samples as valid)
g_loss = self.combined.train_on_batch(noise, valid)
# Print the progress
# print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
if epoch % sample_interval == 0:
image_summary = tf.Summary(value=[tf.Summary.Value(tag='fake', image=self.get_visualization(epoch))])
self.writer.add_summary(image_summary, epoch)
if epoch % sample_interval == 0:
summary = tf.Summary(value=[
tf.Summary.Value(tag="loss/D_loss", simple_value=d_loss[0]),
])
self.writer.add_summary(summary, epoch)
summary = tf.Summary(value=[
tf.Summary.Value(tag="D_loss/D_loss_real", simple_value=d_loss_real[0]),
])
self.writer.add_summary(summary, epoch)
summary = tf.Summary(value=[
tf.Summary.Value(tag="D_loss/D_loss_fake", simple_value=d_loss_fake[0]),
])
self.writer.add_summary(summary, epoch)
summary = tf.Summary(value=[
tf.Summary.Value(tag="loss/Acc", simple_value=100*d_loss[1]),
])
self.writer.add_summary(summary, epoch)
summary = tf.Summary(value=[
tf.Summary.Value(tag="D_loss/Acc_real", simple_value=100*d_loss_real[1]),
])
self.writer.add_summary(summary, epoch)
summary = tf.Summary(value=[
tf.Summary.Value(tag="D_loss/Acc_fake", simple_value=100*d_loss_fake[1]),
])
self.writer.add_summary(summary, epoch)
summary = tf.Summary(value=[
tf.Summary.Value(tag="loss/G_loss", simple_value=g_loss),
])
self.writer.add_summary(summary, epoch)
if __name__ == '__main__':
print_env_info()
if os.path.exists('logs'):
shutil.rmtree('logs')
if os.path.exists('images'):
shutil.rmtree('images')
os.makedirs('images')
gan = GAN()
gan.train(epochs=10000, batch_size=32, sample_interval=200)