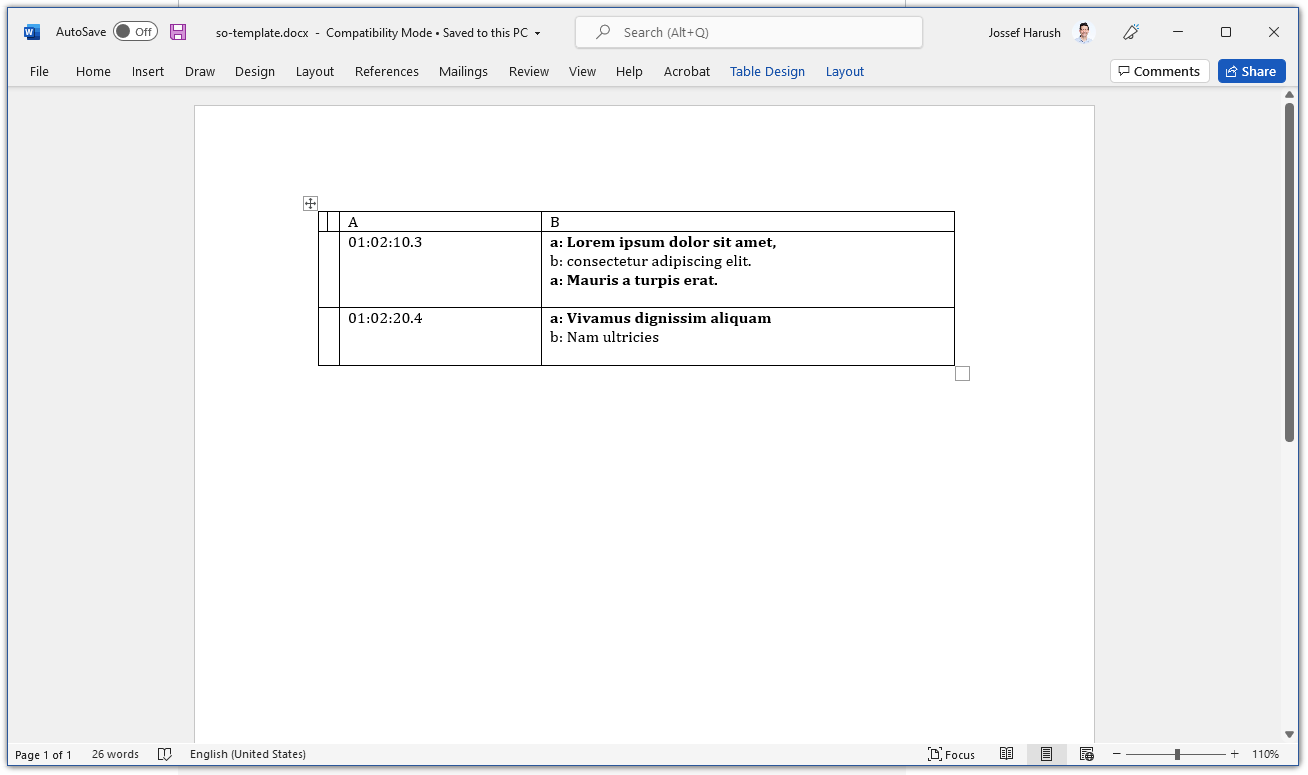
I'm using python-docx to create a document with a table I want to populate from textual data. My text looks like this:
01:02:10.3
a: Lorem ipsum dolor sit amet,
b: consectetur adipiscing elit.
a: Mauris a turpis erat.
01:02:20.4
a: Vivamus dignissim aliquam
b: Nam ultricies
(etc.)
I need to organize it in a table like this (using ASCII for visualization):
+---+--------------------+---------------------------------+
| | A | B |
+---+--------------------+---------------------------------+
| 1 | 01:02:10.3 | a: Lorem ipsum dolor sit amet, |
| 2 | | b: consectetur adipiscing elit. |
| 3 | | a: Mauris a turpis erat. |
| 4 | ------------------ | ------------------------------- |
| 5 | 01:02:20.4 | a: Vivamus dignissim aliqua |
| 6 | | b: Nam ultricies |
+---+--------------------+---------------------------------+
however, I need to make it so everything after "a: " is bold, and everything after "b: " isn't, while they both occupy the same cell. It's pretty easy to iterate and organize this the way I want, but I'm really unsure about how to make only some of the lines bold:
IS_BOLD = {
'a': True
'b': False
}
row_cells = table.add_row().cells
for line in lines:
if is_timestamp(line): # function that uses regex to discern between columns
if row_cells[1]:
row_cells = table.add_row().cells
row_cells[0].text = line
else
row_cells[1].text += line
if IS_BOLD[ line.split(":")[0] ]:
# make only this line within the cell bold, somehow.
(this is sort of pseudo-code, I'm doing some more textual processing but that's kinda irrelevant here). I found one probably relevant question where someone uses something called run but I'm finding it hard to understand how to apply it to my case.
Any help? Thanks.