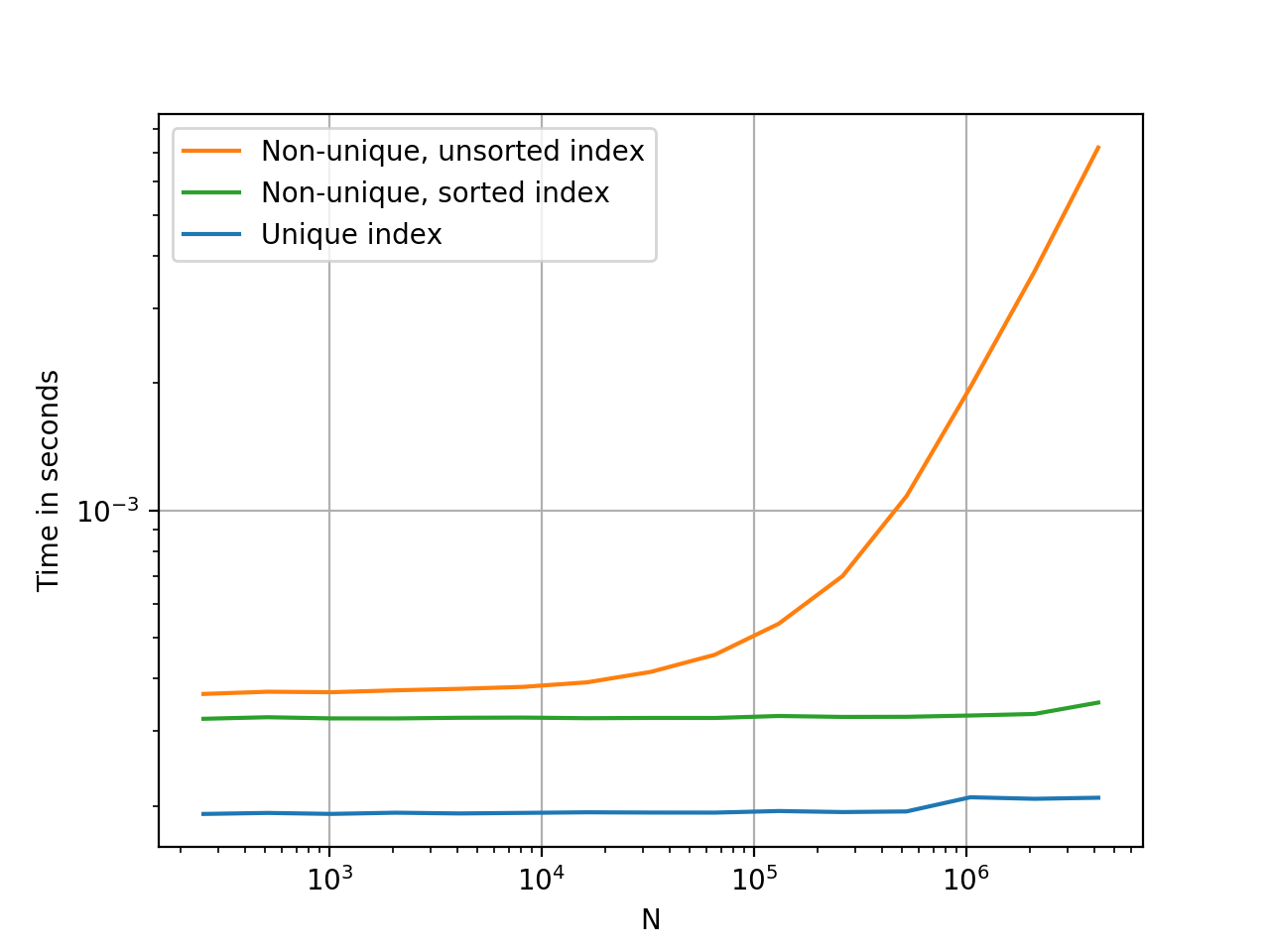
From the pandas documentation, I've gathered that unique-valued indices make certain operations efficient, and that non-unique indices are occasionally tolerated.
From the outside, it doesn't look like non-unique indices are taken advantage of in any way. For example, the following ix query is slow enough that it seems to be scanning the entire dataframe
In [23]: import numpy as np
In [24]: import pandas as pd
In [25]: x = np.random.randint(0, 10**7, 10**7)
In [26]: df1 = pd.DataFrame({'x':x})
In [27]: df2 = df1.set_index('x', drop=False)
In [28]: %timeit df2.ix[0]
1 loops, best of 3: 402 ms per loop
In [29]: %timeit df1.ix[0]
10000 loops, best of 3: 123 us per loop
(I realize the two ix queries don't return the same thing -- it's just an example that calls to ix on a non-unique index appear much slower)
Is there any way to coax pandas into using faster lookup methods like binary search on non-unique and/or sorted indices?