I ran into an interesting problem in a system where due to a schema change, a first database transaction in a single thread blocks a second database transaction from completing, until a timeout occurs.
To test this I created a test database:
CREATE DATABASE StackOverflow
GO
USE StackOverflow
ALTER DATABASE StackOverflow SET ALLOW_SNAPSHOT_ISOLATION ON
ALTER DATABASE StackOverflow SET READ_COMMITTED_SNAPSHOT ON WITH ROLLBACK IMMEDIATE
GO
CREATE TABLE One (
Id int CONSTRAINT pkOne PRIMARY KEY,
A varchar(10) NOT NULL
)
CREATE TABLE Two (
Id int CONSTRAINT pkTwo PRIMARY KEY,
B varchar(10) NOT NULL,
OneId int NOT NULL CONSTRAINT fkTwoToOne REFERENCES One
)
GO
-----------------------------------------------
CREATE TABLE Three (
Id int CONSTRAINT pkThree PRIMARY KEY,
SurrogateId int NOT NULL CONSTRAINT ThreeSurrUnique UNIQUE,
C varchar(10) NOT NULL
)
GO
CREATE TABLE Four (
Id int CONSTRAINT pkFour PRIMARY KEY,
D varchar(10) NOT NULL,
ThreeSurrogateId int NOT NULL CONSTRAINT fkFourToThree REFERENCES Three(SurrogateId)
)
GO
--Seed data
INSERT INTO One (Id, A) VALUES (1, '')
INSERT INTO Three (Id, SurrogateId, C) VALUES (3, 50, '')
In this first test, a transaction modifying a row in table One is started, but not yet committed. Another transaction is inserting into table Two, with a column referencing the same row being modified in the first transaction in table One. The second transaction will hang forever until the first transaction is committed.
The reason the transaction waits is due to a LCK_M_S keylock held by the first transaction.

In my second test, a transaction modifying a row in table Three is started, but not yet committed, just as in the first test. Another transaction is inserting into table Four, with a column referencing the same row being modified in the first transaction in table Three. Except this time, table Four references a surrogate key in table Three instead of the primary key. The transaction completed immediately and is unaffected by the first transaction.
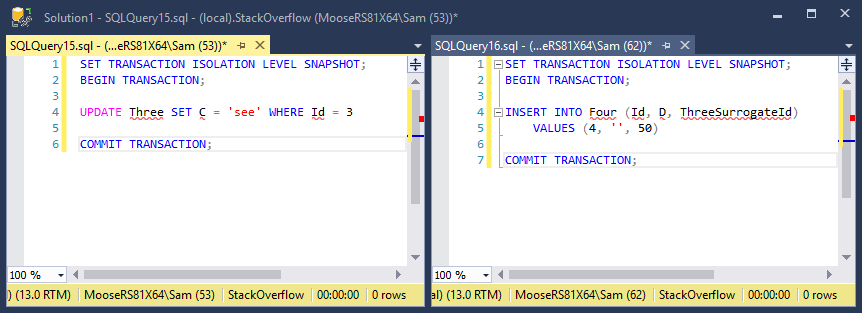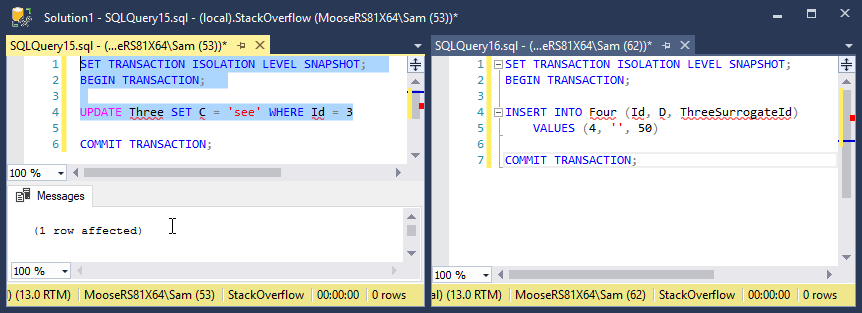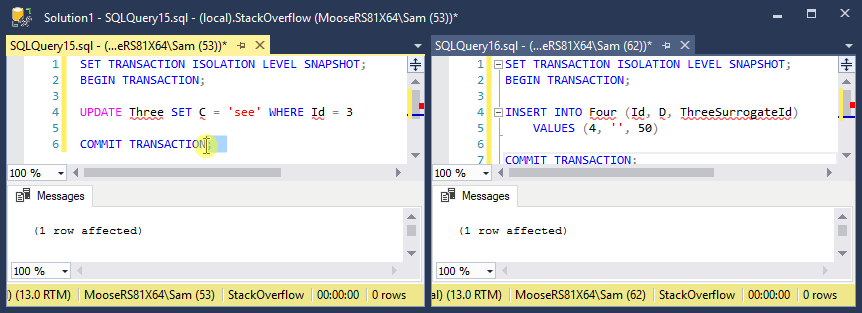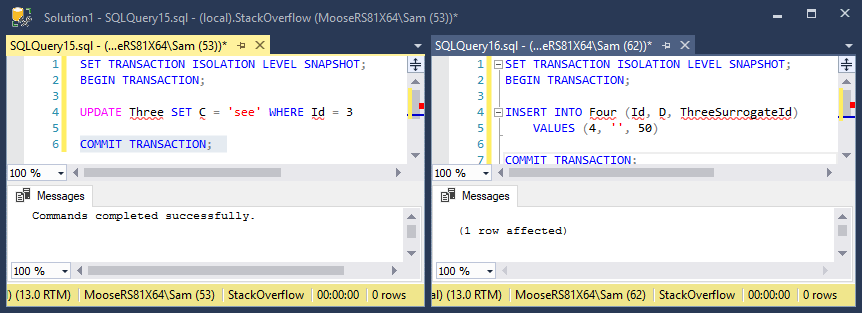
I need help understanding why the the latter transaction is always blocked by the former transaction when inserting a row in a separate table that references a table that was modified in the first transaction. I think the obvious unhelpful answer is because of the foreign key constraint. But why? Especially because this is snapshot isolation, why does the latter transaction care about the former at all? The row it's referencing already exists and the foreign key can easily be verified, as proven by the second test where a foreign key referencing a surrogate key completes without obstruction.