Spring application using Hikari pool.
Now for a single request from the client I have to query 10 tables(business required), and then composite the result together. And querying for each table may cost 50ms to 200ms. To speed up the response time, I create a FixedThreadPool in my service to query each table in different thread(pseudocode):
class MyService{
final int THREAD_POOL_SIZE = 20;
final int CONNECTION_POOL_SIZE = 10;
final ExecutorService pool = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
protected DataSource ds;
MyClass(){
Class.forName(getJdbcDriverName());
HikariConfig config = new HikariConfig();
config.setMaximumPoolSize(CONNECTION_POOL_SIZE);
ds = new HikariDataSource(config);
}
public Items doQuery(){
String[] tables=["a","b"......]; //10+ tables
Items result=new Items();
CompletionService<Items> executorService = new ExecutorCompletionService<Items>(pool);
for (String tb : tables) {
Callable<Item> c = () -> {
Items items = ds.getConnection().query(tb); ......
return Items;
};
executorService.submit(c);
}
for (String tb: tables) {
final Future<Items> future = executorService.take();
Items items = future.get();
result.addAll(items);
}
}
}
Now for a single request, the average response time maybe 500ms.
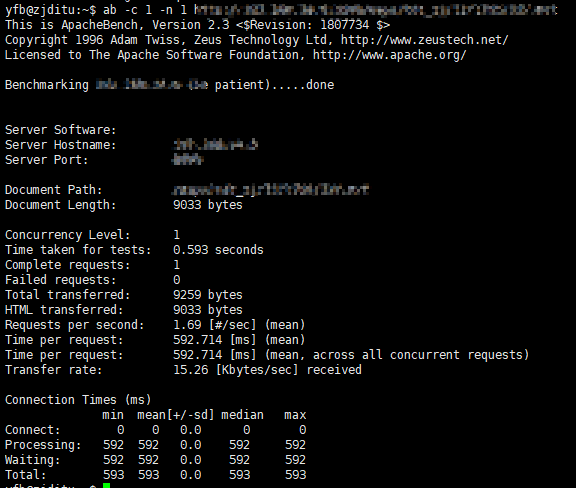
But for concurrent requests, the average response time will increase rapidly, the more the requests, the long the response time will be.
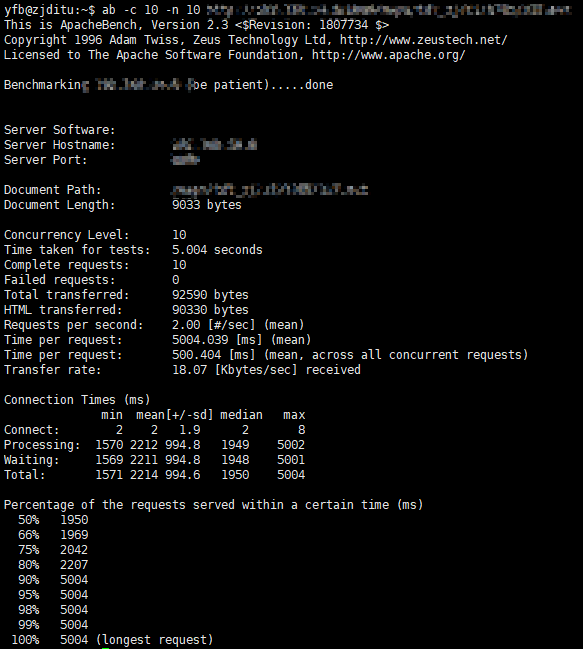
I wonder how to set the proper connection pool size and thread pool size to make the app work effective?
BTW, the database use RDS in cloud with 4 cpu 16GB mem, 2000 max connections and 8000 max IOPS.
Your threading strategy might increase the response time for one request. For a single request, my thread strategy will use 10 threads each use a connection in the pool, which I think may decrease the response. – BantustanFixedThreadPoolin my service to query each table in different thread': this is already fallacious. The database is multi-threaded up to a point, but at some point it has to lock tables, or indexes, and in any case the intervening network isn't multi-threaded. Don't overthink this. – Allege