When reviewing through the Sigmoid function that is used in Neural Nets, we found this equation from https://en.wikipedia.org/wiki/Softmax_function#Softmax_Normalization:
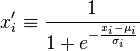
Different from the standard sigmoid equation:
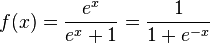
The first equation on top somehow involves the mean and standard deviation (I hope I didn't read the symbols wrongly) whereas the 2nd equation generalized the minus mean and divided by standard deviation as a constant since it's the same throughout all terms within a vector/matrix/tensor.
So when implementing the equations, I get different results.
With the 2nd equation (standard sigmoid function):
def sigmoid(x):
return 1. / (1 + np.exp(-x))
I get these output:
>>> x = np.array([1,2,3])
>>> print sigmoid(x)
[ 0.73105858 0.88079708 0.95257413]
I would have expect the 1st function to be the similar but the gap between the first and second element widens by quite a bit (though the ranking of the elements remains:
def get_statistics(x):
n = float(len(x))
m = x.sum() / n
s2 = sum((x - m)**2) / (n-1.)
s = s2**0.5
return m, s2, s
m, s, s2 = get_statistics(x)
sigmoid_x1 = 1 / (1 + np.exp(-(x[0] - m) / s2))
sigmoid_x2 = 1 / (1 + np.exp(-(x[1] - m) / s2))
sigmoid_x3 = 1 / (1 + np.exp(-(x[2] - m) / s2))
sigmoid_x1, sigmoid_x2, sigmoid_x3
[out]:
(0.2689414213699951, 0.5, 0.7310585786300049)
Possibly it has to do with the fact that the first equation contains some sort of softmax normalization but if it's generic softmax then the elements need to sum to one as such:
def softmax(x):
exp_x = np.exp(x)
return exp_x / exp_x.sum()
[out]:
>>> x = np.array([1,2,3])
>>> print softmax(x)
[ 0.09003057 0.24472847 0.66524096]
But the output from the first equation don't sum to one and it isn't similar/same as the standard sigmoid equation. So the question is:
- Have I implemented the function for equation 1 wrongly?
- Is equation 1 on the wikipedia page wrong? Or is it referring to something else and not really the sigmoid/logistic function?
- Why is there a difference in the first and second equation?