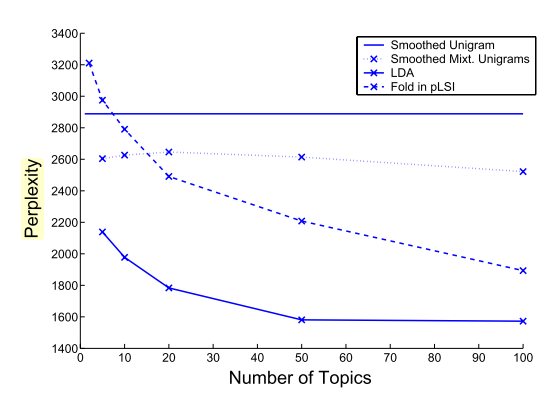
I'd like to know what does the perplexity and score means in the LDA implementation of Scikit-learn. Those functions are obscure.
At the very least, I need to know if those values increase or decrease when the model is better. I've searched but it's somehow unclear. I feel that the perplexity should go down, but I'd like a clear answer on how those values should go up or down.