I know both is performed on a column in the table but how is each operation different.
What is the difference between partitioning and bucketing a table in Hive ?
Partitioning data is often used for distributing load horizontally, this has performance benefit, and helps in organizing data in a logical fashion. Example: if we are dealing with a large employee table and often run queries with WHERE clauses that restrict the results to a particular country or department . For a faster query response Hive table can be PARTITIONED BY (country STRING, DEPT STRING). Partitioning tables changes how Hive structures the data storage and Hive will now create subdirectories reflecting the partitioning structure like
.../employees/country=ABC/DEPT=XYZ.
If query limits for employee from country=ABC, it will only scan the contents of one directory country=ABC. This can dramatically improve query performance, but only if the partitioning scheme reflects common filtering. Partitioning feature is very useful in Hive, however, a design that creates too many partitions may optimize some queries, but be detrimental for other important queries. Other drawback is having too many partitions is the large number of Hadoop files and directories that are created unnecessarily and overhead to NameNode since it must keep all metadata for the file system in memory.
Bucketing is another technique for decomposing data sets into more manageable parts. For example, suppose a table using date as the top-level partition and employee_id as the second-level partition leads to too many small partitions. Instead, if we bucket the employee table and use employee_id as the bucketing column, the value of this column will be hashed by a user-defined number into buckets. Records with the same employee_id will always be stored in the same bucket. Assuming the number of employee_id is much greater than the number of buckets, each bucket will have many employee_id. While creating table you can specify like CLUSTERED BY (employee_id) INTO XX BUCKETS; where XX is the number of buckets . Bucketing has several advantages. The number of buckets is fixed so it does not fluctuate with data. If two tables are bucketed by employee_id, Hive can create a logically correct sampling. Bucketing also aids in doing efficient map-side joins etc.
Thanks Navneet. However, can you elaborate how bucketing happens with partitioning ? Suppose if we specify 32 buckets in the CLUSED BY clause and the CREATE TABLE statement also contains the Partitioning clause, how partitions and buckets will be managed together ? Does number of partitions will be limited to 32 ? OR for each partition, 32 buckets will be created ? Is every bucket an HDFS file ? –
Detrusion
A hive table can have both partitioning and bucketing. Based on your partition clause , for each partition will have 32 buckets created. Yes HDFS file. –
Meerschaum
@Detrusion Partition is a folder, bucket is a file. –
Slug
For the record, this answer derives from the text of Programming Hive (O'Reilly, 2012). –
Tryout
I found this link useful. It has information that will add more value to this answer. linkedin.com/pulse/… –
Gangland
Can one column be partitioned as well bucketed? create table emp (name string)partitioned by(id int) clustered by(id) into 4 buckets; This gives: FAILED: SemanticException [Error 10002]: Invalid column reference. Is this possible to do? If yes, then what is the correct syntax? –
Caddy
As per your scenario, if employee_id are more than 1000 and I mention 256 buckets. How this will be handled in Bucketting? Will it throw an error? –
Pincince
can you update just specific bucket within partition with
insert overwrite statement? –
Vaclav There are a few details missing from the previous explanations. To better understand how partitioning and bucketing works, you should look at how data is stored in hive. Let's say you have a table
CREATE TABLE mytable (
name string,
city string,
employee_id int )
PARTITIONED BY (year STRING, month STRING, day STRING)
CLUSTERED BY (employee_id) INTO 256 BUCKETS
then hive will store data in a directory hierarchy like
/user/hive/warehouse/mytable/y=2015/m=12/d=02
So, you have to be careful when partitioning, because if you for instance partition by employee_id and you have millions of employees, you'll end up having millions of directories in your file system. The term 'cardinality' refers to the number of possible value a field can have. For instance, if you have a 'country' field, the countries in the world are about 300, so cardinality would be ~300. For a field like 'timestamp_ms', which changes every millisecond, cardinality can be billions. In general, when choosing a field for partitioning, it should not have a high cardinality, because you'll end up with way too many directories in your file system.
Clustering aka bucketing on the other hand, will result with a fixed number of files, since you do specify the number of buckets. What hive will do is to take the field, calculate a hash and assign a record to that bucket. But what happens if you use let's say 256 buckets and the field you're bucketing on has a low cardinality (for instance, it's a US state, so can be only 50 different values) ? You'll have 50 buckets with data, and 206 buckets with no data.
Someone already mentioned how partitions can dramatically cut the amount of data you're querying. So in my example table, if you want to query only from a certain date forward, the partitioning by year/month/day is going to dramatically cut the amount of IO. I think that somebody also mentioned how bucketing can speed up joins with other tables that have exactly the same bucketing, so in my example, if you're joining two tables on the same employee_id, hive can do the join bucket by bucket (even better if they're already sorted by employee_id since it's going to mergesort parts that are already sorted, which works in linear time aka O(n) ).
So, bucketing works well when the field has high cardinality and data is evenly distributed among buckets. Partitioning works best when the cardinality of the partitioning field is not too high.
Also, you can partition on multiple fields, with an order (year/month/day is a good example), while you can bucket on only one field.
Can you please explain the CLUSTERED-BY behavior with SORTED-BY in an example? As per my example I found SORTED-BY doing nothing. Am I missing anything. –
Villada
CLUSTERED BY x,y is like writing DISTRIBUTE BY x,y SORT BY x,y (see cwiki.apache.org/confluence/display/Hive/…) so adding SORT BY to CLUSTERED BY has no effect. –
Threatt
Interesting, I agree w.r.t the usage in select query. But wondered why people are using clustered by and sorted by together in table creation statement. If there is no significance to SORTED BY in DDL, then why this keyword is present? Didnt get that. –
Villada
SORTED BY is meant to be used with DISTRIBUTED BY. For instance, you may want to distributed by user id and sort by time within the bucket. CLUSTER BY is just a shortcut for when the clause on the SORTED BY and DISTRIBUTED BY are the same. Only thing I can think about is if you're distributing by x,y and sorting by x,y and z –
Threatt
I am not sure what you mean by "you can bucket on only one field." I think it is possible to bucket by multiple fields the hashing function will just take all of the fields and combine them. –
Tiepolo
You're right, it's not completely correct, what I meant is that you can partition through several dimensions, while bucketing you can do it only through one dimension, may it be a single field or a combination of them. As you said, you have a hashing function that reduces multiple fields to one field (the hash value). –
Threatt
"mergesort which works in linear time..." You mean just a merge not a mergesort here I believe, mergesort is always O(n*log(n)) –
Connolly
Not always.....if the parts being merged are already sorted like in the example I was mentioning, it works in linear time. But good point, I'll ad a clarification. –
Threatt
This is my favorite answer. Even tho Navneet Kumar's answer describes both bucketing and partitioning very well, this answer more clearly lays out the differences –
Mezereum
Before going into Bucketing, we need to understand what Partitioning is. Let us take the below table as an example. Note that I have given only 12 records in the below example for beginner level understanding. In real-time scenarios you might have millions of records.
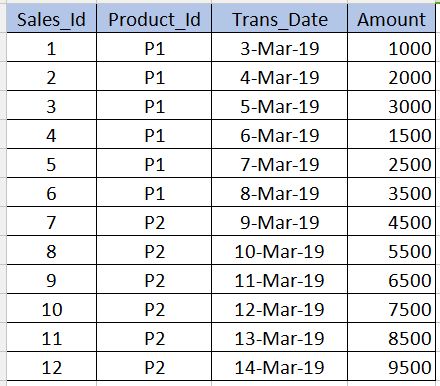
PARTITIONING
---------------------
Partitioning is used to obtain performance while querying the data. For example, in the above table, if we write the below sql, it need to scan all the records in the table which reduces the performance and increases the overhead.
select * from sales_table where product_id='P1'
To avoid full table scan and to read only the records related to product_id='P1' we can partition (split hive table's files) into multiple files based on the product_id column. By this the hive table's file will be split into two files one with product_id='P1' and other with product_id='P2'. Now when we execute the above query, it will scan only the product_id='P1' file.
../hive/warehouse/sales_table/product_id=P1
../hive/warehouse/sales_table/product_id=P2
The syntax for creating the partition is given below. Note that we should not use the product_id column definition along with the non-partitioned columns in the below syntax. This should be only in the partitioned by clause.
create table sales_table(sales_id int,trans_date date, amount int)
partitioned by (product_id varchar(10))
Cons : We should be very careful while partitioning. That is, it should not be used for the columns where number of repeating values are very less (especially primary key columns) as it increases the number of partitioned files and increases the overhead for the Name node.
BUCKETING
------------------
Bucketing is used to overcome the cons that I mentioned in the partitioning section. This should be used when there are very few repeating values in a column (example - primary key column). This is similar to the concept of index on primary key column in the RDBMS. In our table, we can take Sales_Id column for bucketing. It will be useful when we need to query the sales_id column.
Below is the syntax for bucketing.
create table sales_table(sales_id int,trans_date date, amount int)
partitioned by (product_id varchar(10)) Clustered by(Sales_Id) into 3 buckets
Here we will further split the data into few more files on top of partitions.
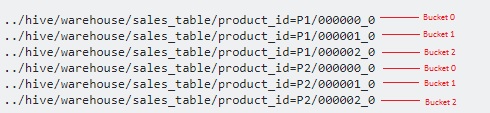
Since we have specified 3 buckets, it is split into 3 files each for each product_id. It internally uses modulo operator to determine in which bucket each sales_id should be stored. For example, for the product_id='P1', the sales_id=1 will be stored in 000001_0 file (ie, 1%3=1), sales_id=2 will be stored in 000002_0 file (ie, 2%3=2),sales_id=3 will be stored in 000000_0 file (ie, 3%3=0) etc.
For numeric clustered columns, does it always just take mod by the number of buckets? For string-valued clustered columns, does it use the Java
hashCode() of the string as the hash function? Can the programmer choose the hash function? –
Harvin Apparently (and per my experiments) hive uses a variation on Java's hashCode() method: github.com/apache/hive/blob/release-1.1.0/serde/src/java/org/… . This was mentioned here: #30594538 . –
Harvin
I think I am late in answering this question, but it keep coming up in my feed.
Navneet has provided excellent answer. Adding to it visually.
Partitioning helps in elimination of data, if used in WHERE clause, where as bucketing helps in organizing data in each partition into multiple files, so as same set of data is always written in same bucket. Helps a lot in joining of columns.
Suppose, you have a table with five columns, name, server_date, some_col3, some_col4 and some_col5. Suppose, you have partitioned the table on server_date and bucketed on name column in 10 buckets, your file structure will look something like below.
- server_date=xyz
- 00000_0
- 00001_0
- 00002_0
- ........
- 00010_0
Here server_date=xyz is the partition and 000 files are the buckets in each partition. Buckets are calculated based on some hash functions, so rows with name=Sandy will always go in same bucket.
According to Roberto in above answer server_date would be a bad example to do partitioning as it's cardinality value is really high. And so you will end up having too many folders in hdfs. –
Indic
server_date is mentioned as an example here. In real world, the partition generally happens as depicted by Roberto, by breaking the date into year/month/day. That's how it should be. –
Strikebreaker
Hive Partitioning:
Partition divides large amount of data into multiple slices based on value of a table column(s).
Assume that you are storing information of people in entire world spread across 196+ countries spanning around 500 crores of entries. If you want to query people from a particular country (Vatican city), in absence of partitioning, you have to scan all 500 crores of entries even to fetch thousand entries of a country. If you partition the table based on country, you can fine tune querying process by just checking the data for only one country partition. Hive partition creates a separate directory for a column(s) value.
Pros:
- Distribute execution load horizontally
- Faster execution of queries in case of partition with low volume of data. e.g. Get the population from "Vatican city" returns very fast instead of searching entire population of world.
Cons:
- Possibility of too many small partition creations - too many directories.
- Effective for low volume data for a given partition. But some queries like group by on high volume of data still take long time to execute. e.g. Grouping of population of China will take long time compared to grouping of population in Vatican city. Partition is not solving responsiveness problem in case of data skewing towards a particular partition value.
Hive Bucketing:
Bucketing decomposes data into more manageable or equal parts.
With partitioning, there is a possibility that you can create multiple small partitions based on column values. If you go for bucketing, you are restricting number of buckets to store the data. This number is defined during table creation scripts.
Pros
- Due to equal volumes of data in each partition, joins at Map side will be quicker.
- Faster query response like partitioning
Cons
- You can define number of buckets during table creation but loading of equal volume of data has to be done manually by programmers.
The difference is bucketing divides the files by Column Name, and partitioning divides the files under By a particular value inside table
Hopefully I defined it correctly
There are great responses here. I would like to keep it short to memorize the difference between partition & buckets.
You generally partition on a less unique column. And bucketing on most unique column.
Example if you consider World population with country, person name and their bio-metric id as an example. As you can guess, country field would be the less unique column and bio-metric id would be the most unique column. So ideally you would need to partition the table by country and bucket it by bio-metric id.
Using Partitions in Hive table is highly recommended for below reason -
- Insert into Hive table should be faster ( as it uses multiple threads to write data to partitions )
- Query from Hive table should be efficient with low latency.
Example :-
Assume that Input File (100 GB) is loaded into temp-hive-table and it contains bank data from across different geographies.
Hive table without Partition
Insert into Hive table Select * from temp-hive-table
/hive-table-path/part-00000-1 (part size ~ hdfs block size)
/hive-table-path/part-00000-2
....
/hive-table-path/part-00000-n
Problem with this approach is - It will scan whole data for any query you run on this table. Response time will be high compare to other approaches where partitioning and Bucketing are used.
Hive table with Partition
Insert into Hive table partition(country) Select * from temp-hive-table
/hive-table-path/country=US/part-00000-1 (file size ~ 10 GB)
/hive-table-path/country=Canada/part-00000-2 (file size ~ 20 GB)
....
/hive-table-path/country=UK/part-00000-n (file size ~ 5 GB)
Pros - Here one can access data faster when it comes to querying data for specific geography transactions. Cons - Inserting/querying data can further be improved by splitting data within each partition. See Bucketing option below.
Hive table with Partition and Bucketing
Note: Create hive table ..... with "CLUSTERED BY(Partiton_Column) into 5 buckets
Insert into Hive table partition(country) Select * from temp-hive-table
/hive-table-path/country=US/part-00000-1 (file size ~ 2 GB)
/hive-table-path/country=US/part-00000-2 (file size ~ 2 GB)
/hive-table-path/country=US/part-00000-3 (file size ~ 2 GB)
/hive-table-path/country=US/part-00000-4 (file size ~ 2 GB)
/hive-table-path/country=US/part-00000-5 (file size ~ 2 GB)
/hive-table-path/country=Canada/part-00000-1 (file size ~ 4 GB)
/hive-table-path/country=Canada/part-00000-2 (file size ~ 4 GB)
/hive-table-path/country=Canada/part-00000-3 (file size ~ 4 GB)
/hive-table-path/country=Canada/part-00000-4 (file size ~ 4 GB)
/hive-table-path/country=Canada/part-00000-5 (file size ~ 4 GB)
....
/hive-table-path/country=UK/part-00000-1 (file size ~ 1 GB)
/hive-table-path/country=UK/part-00000-2 (file size ~ 1 GB)
/hive-table-path/country=UK/part-00000-3 (file size ~ 1 GB)
/hive-table-path/country=UK/part-00000-4 (file size ~ 1 GB)
/hive-table-path/country=UK/part-00000-5 (file size ~ 1 GB)
Pros - Faster Insert. Faster Query.
Cons - Bucketing will creating more files. There could be issue with many small files in some specific cases
Hope this will help !!
I think,
Bucketing = Distribution of data in the case when no of columns causing redundant data is more. Therefore, we select the column which has unique data as bucketing key
Partitioning= Distribution of data in the case when no of columns causing redundant data is less. Therefore, we select the column which is causing redundancy.
Id1 id2 value
eg. 1 2 3
1 2 4
1 2 5
if i apply partitioning in such scenario i would be selecting either id1 or id2 so in this case suppose i select id1 so itll give me only 1 partition with 1-> (2->3,4,5) so this way i wont get benefit in the performance even if i club id1 and id2 but suppose i make 3 buckets having value as key so this way ill get 3 buckets with value 3, 4, 5 equally distributed with 2 values as 1 & 2.
The taking from the above eg. is this is when huge data is there eg. above contains just one set of columns with way less data but suppose when data is huge the partition key column gets uneven especially in hdfs where distribution matters a lot. So, making just one partition and filling it again and again by nesting another partition like column will cause performance issues this is where bucketing helps.
Thanks, any corrections are welcomed.
© 2022 - 2024 — McMap. All rights reserved.