I am generating a pdf from a set of Jupyter notebooks. For each .ipynb file, I'm running
$ jupyter-nbconvert --to markdown Untitled1.ipynb
and then merging them together with:
$ pandoc Untitled1.md [Untitled2.md ...] -f gfm --pdf-engine=pdflatex -o all_notebooks.pdf
(I am mostly following the example here.) One thing I noticed is that the pandas DataFrames, e.g.
import pandas as pd
df = pd.DataFrame({'a':[1,2,3]})
df.head()
are rendered in the pdf as

rather than
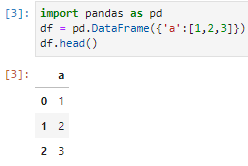
Any idea how to fix this issue, please? I am using $ jupyter-nbconvert --version 5.6.1 and $ pandoc --version 2.9.2.1. In the md file the table turns into the html block below. I suspect pandoc does not interpret it correctly. I tried the from-markdown-strict option suggested here, without any luck.
Thank you!
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>a</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>1</td>
</tr>
<tr>
<th>1</th>
<td>2</td>
</tr>
<tr>
<th>2</th>
<td>3</td>
</tr>
</tbody>
</table>
</div>