I understand the basic steps of creating an automated speech recognition engine. However, I need a clear-er idea of how segmentation is done and what are frames and samples. I will write down what I know and expect the answer-er to correct me in the places where I'm wrong and guide me further.
The basic steps of Speech Recognition as I know it are:
(I'm assuming the input data is a wav/ogg (or some kind of audio) file)
- Pre-emphasize the speech signal : i.e., Apply a filter that will put an emphasis to high frequency signals. Possibly something like: y[n] = x[n] - 0.95 x[n-1]
- Find the time from which the utterances start and resize the clip. (Interchangable with Step 1)
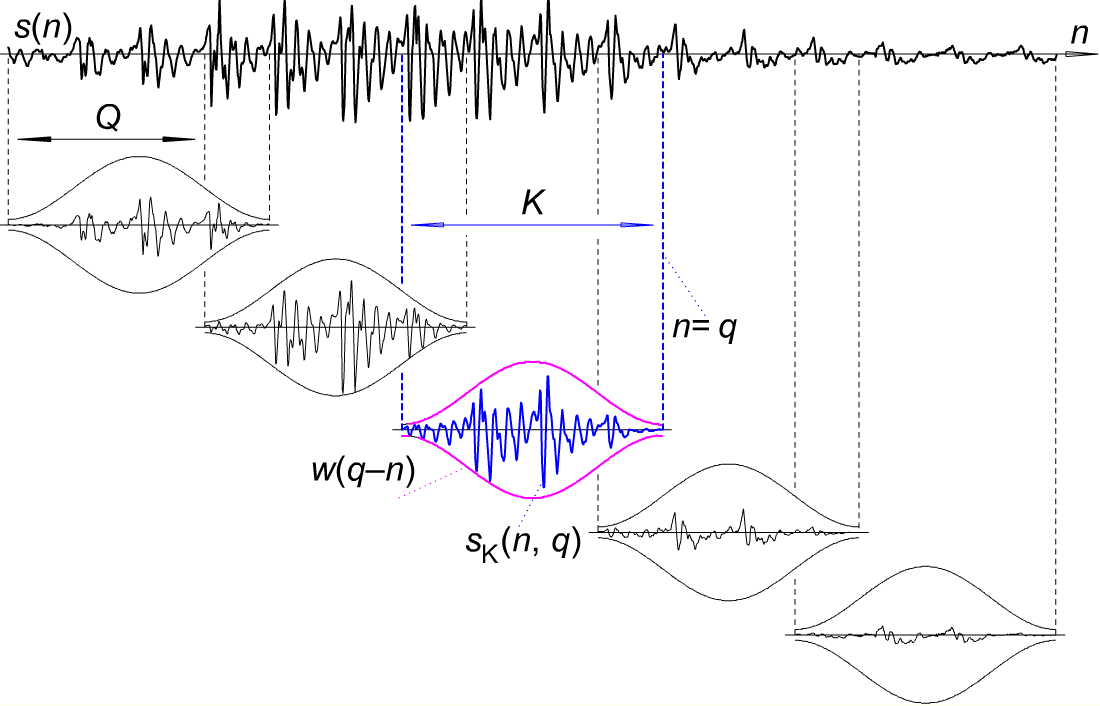
- Segment the clip into smaller time frames, each segment being like 30msecs long. Further, Each segment will have about 256 Frames and two segments will have a seperation of 100 Frames? (i.e., 30*100/256 msec ?)
- Apply Hamming Window to each frame (1/256th of a segment)? The result is a array of frame of signals.
- Fast Fourier Transform the signal of each frame represented by X(t)
- Mel Filter Bank Processing: (Not yet Went into Detail)
- Discrete Cosine Transform: (Not yet Went into Detail - but know that this will give me a set of MFCCs, also called acoustic vectors for each input utterance.
- Delta Energy and Delta Spectrum: I Know that this is used to calculate delta and double delta coefficients of MFCCs, not much.
- After this, I think I need to use HMMs or ANNs to classify the Mel Frequency Cepstrum Coefficients (delta and double delta) to corresponding phonemes and perform analysis to match the phonemes to words and respectively words to sentences.
Although these are clear to me, I am confused if step 3 is correct. If It is correct, In the steps following 3, do I apply that to each frame? Also, after step 6, I think that each frame has their own set of MFCC, am I right?
Thank you in advance!
import librosa y, sr = librosa.load('./data/tring/abcd.wav') mfcc=librosa.feature.mfcc(y=y, sr=sr)– Haskel