We are having performance issues when using the CUDA Dynamic Parallelism. At this moment, CDP is performing at least 3X slower than a traditional approach. We made the simplest reproducible code to show this issue, which is to increment the value of all elements of an array by +1. i.e.,
a[0,0,0,0,0,0,0,.....,0] --> kernel +1 --> a[1,1,1,1,1,1,1,1,1]
The point of this simple example is just to see if CDP can perform as the others, or if there are serious overheads.
The code is here:
#include <stdio.h>
#include <cuda.h>
#define BLOCKSIZE 512
__global__ void kernel_parent(int *a, int n, int N);
__global__ void kernel_simple(int *a, int n, int N, int offset);
// N is the total array size
// n is the worksize for a kernel (one third of N)
__global__ void kernel_parent(int *a, int n, int N){
cudaStream_t s1, s2;
cudaStreamCreateWithFlags(&s1, cudaStreamNonBlocking);
cudaStreamCreateWithFlags(&s2, cudaStreamNonBlocking);
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if(tid == 0){
dim3 block(BLOCKSIZE, 1, 1);
dim3 grid( (n + BLOCKSIZE - 1)/BLOCKSIZE, 1, 1);
kernel_simple<<< grid, block, 0, s1 >>> (a, n, N, n);
kernel_simple<<< grid, block, 0, s2 >>> (a, n, N, 2*n);
}
a[tid] += 1;
}
__global__ void kernel_simple(int *a, int n, int N, int offset){
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int pos = tid + offset;
if(pos < N){
a[pos] += 1;
}
}
int main(int argc, char **argv){
if(argc != 3){
fprintf(stderr, "run as ./prog n method\nn multiple of 32 eg: 1024, 1048576 (1024^2), 4194304 (2048^2), 16777216 (4096^2)\nmethod:\n0 (traditional) \n1 (dynamic parallelism)\n2 (three kernels using unique streams)\n");
exit(EXIT_FAILURE);
}
int N = atoi(argv[1])*3;
int method = atoi(argv[2]);
// init array as 0
int *ah, *ad;
printf("genarray of 3*N = %i.......", N); fflush(stdout);
ah = (int*)malloc(sizeof(int)*N);
for(int i=0; i<N; ++i){
ah[i] = 0;
}
printf("done\n"); fflush(stdout);
// malloc and copy array to gpu
printf("cudaMemcpy:Host->Device..........", N); fflush(stdout);
cudaMalloc(&ad, sizeof(int)*N);
cudaMemcpy(ad, ah, sizeof(int)*N, cudaMemcpyHostToDevice);
printf("done\n"); fflush(stdout);
// kernel launch (timed)
cudaStream_t s1, s2, s3;
cudaStreamCreateWithFlags(&s1, cudaStreamNonBlocking);
cudaStreamCreateWithFlags(&s2, cudaStreamNonBlocking);
cudaStreamCreateWithFlags(&s3, cudaStreamNonBlocking);
cudaEvent_t start, stop;
float rtime = 0.0f;
cudaEventCreate(&start);
cudaEventCreate(&stop);
printf("Kernel...........................", N); fflush(stdout);
if(method == 0){
// CLASSIC KERNEL LAUNCH
dim3 block(BLOCKSIZE, 1, 1);
dim3 grid( (N + BLOCKSIZE - 1)/BLOCKSIZE, 1, 1);
cudaEventRecord(start, 0);
kernel_simple<<< grid, block >>> (ad, N, N, 0);
cudaDeviceSynchronize();
cudaEventRecord(stop, 0);
}
else if(method == 1){
// DYNAMIC PARALLELISM
dim3 block(BLOCKSIZE, 1, 1);
dim3 grid( (N/3 + BLOCKSIZE - 1)/BLOCKSIZE, 1, 1);
cudaEventRecord(start, 0);
kernel_parent<<< grid, block, 0, s1 >>> (ad, N/3, N);
cudaDeviceSynchronize();
cudaEventRecord(stop, 0);
}
else{
// THREE CONCURRENT KERNEL LAUNCHES USING STREAMS
dim3 block(BLOCKSIZE, 1, 1);
dim3 grid( (N/3 + BLOCKSIZE - 1)/BLOCKSIZE, 1, 1);
cudaEventRecord(start, 0);
kernel_simple<<< grid, block, 0, s1 >>> (ad, N/3, N, 0);
kernel_simple<<< grid, block, 0, s2 >>> (ad, N/3, N, N/3);
kernel_simple<<< grid, block, 0, s3 >>> (ad, N/3, N, 2*(N/3));
cudaDeviceSynchronize();
cudaEventRecord(stop, 0);
}
printf("done\n"); fflush(stdout);
printf("cudaMemcpy:Device->Host..........", N); fflush(stdout);
cudaMemcpy(ah, ad, sizeof(int)*N, cudaMemcpyDeviceToHost);
printf("done\n"); fflush(stdout);
printf("checking result.................."); fflush(stdout);
for(int i=0; i<N; ++i){
if(ah[i] != 1){
fprintf(stderr, "bad element: a[%i] = %i\n", i, ah[i]);
exit(EXIT_FAILURE);
}
}
printf("done\n"); fflush(stdout);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&rtime, start, stop);
printf("rtime: %f ms\n", rtime); fflush(stdout);
return EXIT_SUCCESS;
}
Can be compiled with
nvcc -arch=sm_35 -rdc=true -lineinfo -lcudadevrt -use_fast_math main.cu -o prog
This example can compute the result with 3 methods:
- Simple Kernel: Just a single classic kernel +1 pass on the array.
- Dynamic Parallelism: from main(), call a parent kernel which does +1 on the range [0,N/3), and also calls two child kernels. The first child does +1 in the range [N/3, 2*N/3), the second child in the range [2*N/3,N). Childs are launched using different streams so they can be concurrent.
- Three Streams from Host: This one just launches three non-blocking streams from main(), one for each third of the array.
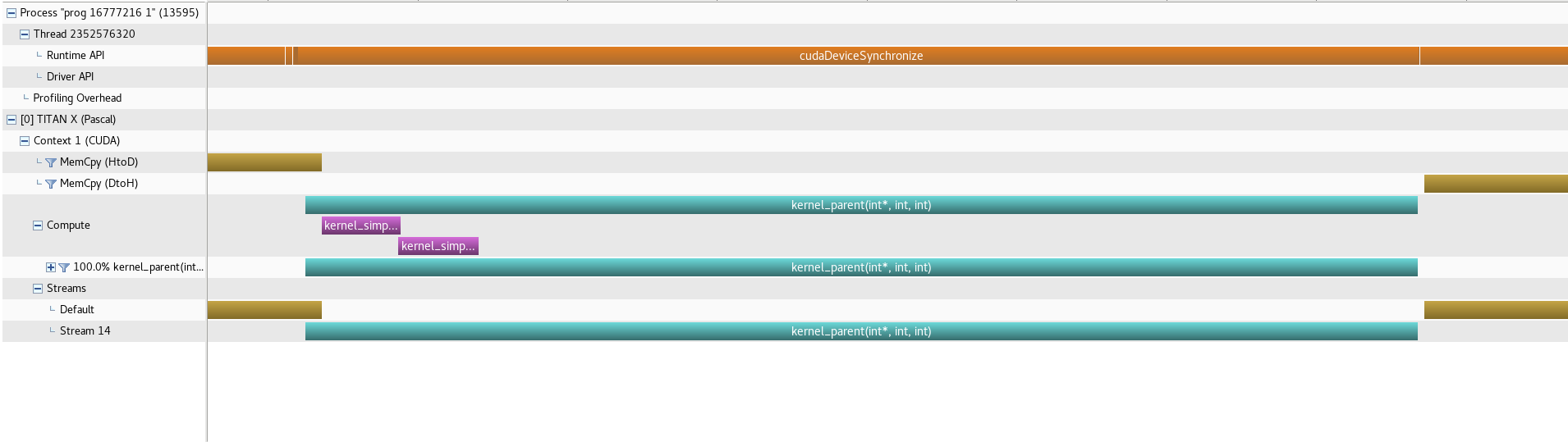
I get the following profile for method 0 (simple kernel):
 The following for method 1 (dynamic parallelism):
The following for method 1 (dynamic parallelism):
 And the following for method 2 (Three Streams from Host)
And the following for method 2 (Three Streams from Host)
 The running times are like this:
The running times are like this:
➜ simple-cdp git:(master) ✗ ./prog 16777216 0
genarray of 3*N = 50331648.......done
cudaMemcpy:Host->Device..........done
Kernel...........................done
cudaMemcpy:Device->Host..........done
checking result..................done
rtime: 1.140928 ms
➜ simple-cdp git:(master) ✗ ./prog 16777216 1
genarray of 3*N = 50331648.......done
cudaMemcpy:Host->Device..........done
Kernel...........................done
cudaMemcpy:Device->Host..........done
checking result..................done
rtime: 5.790048 ms
➜ simple-cdp git:(master) ✗ ./prog 16777216 2
genarray of 3*N = 50331648.......done
cudaMemcpy:Host->Device..........done
Kernel...........................done
cudaMemcpy:Device->Host..........done
checking result..................done
rtime: 1.011936 ms
The main problem, visible from the pictures, is that in the Dynamic Parallelism method the parent kernel is taking excessive amount of time to close after the two child kernels have finished, which is what is making it take 3X or 4X times more. Even when considering the worst case, if all three kernels (parent and two childs) run in serial, it should take much less. I.e., there is N/3 of work for each kernel, so the whole parent kernel should take approx 3 child kernels long, which is much less. Is there a way to solve this problem?
EDIT: The serialization phenomenon of the child kernels, as well as for method 2, have been explained by Robert Crovella in the comments (many thanks). The fact that the kernels did run in serial do not invalidate the problem described in bold text (not for now at least).