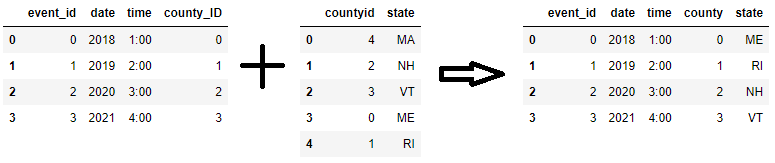
Merging using differently named columns duplicates columns; for example, after the call frame_1.merge(frame_2, how='left', left_on='county_ID', right_on='countyid'), both county_ID and countyid columns are created on the joined frame but they have exactly the same values for every row, so presumably only one of them is needed. To not have this problem from the beginning, rename the merge-key column be the same and merge on that column.
df1 = frame_1.rename(columns={'county_ID':'county'})
df2 = frame_2.rename(columns={'countyid':'county'})
joined_frame = df1.merge(df2, on='county', how='left')
![res1]()
Also, if the second frame has only one new additional column (e.g. state) as in the OP, then you can map that column to frame_1 via the common column.
frame_1['state'] = frame_1['county_ID'].map(frame_2.set_index('countyid')['state'])
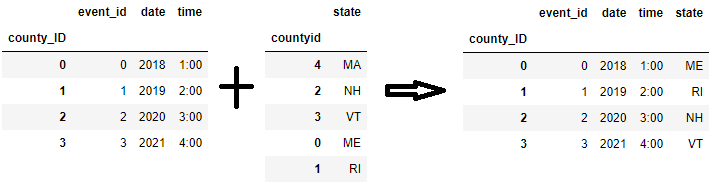
If county_ID and countyid were indices (not columns), then a straightforward join call does the job. By default, it performs left join.
joined_frame = frame_1.join(frame_2)
![res2]()
One nice thing about join is that if you want to join multiple dataframes on index, then you can pass a list of dataframes and join efficiently (instead of multiple chained merge calls).
joined_frame = frame_1.join([frame_2, frame_3])
right_index=True. – Cressi