I want to select a string of Unicode Hebrew text in a Word document and remove the Hebrew vowels (aka nikkud) without changing anything else.
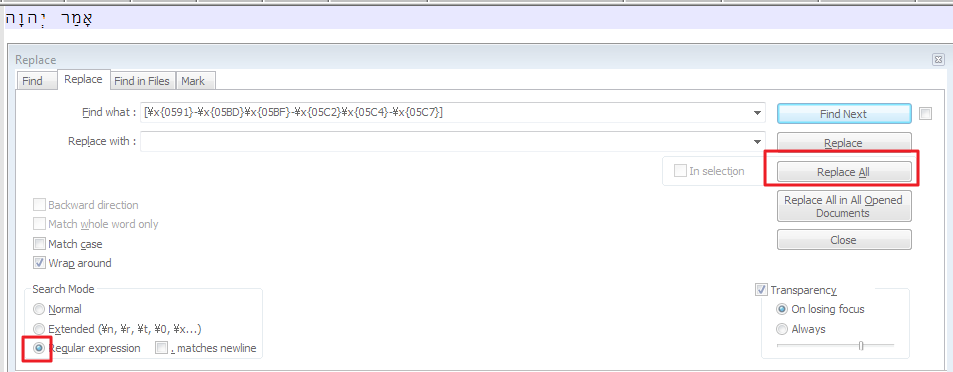
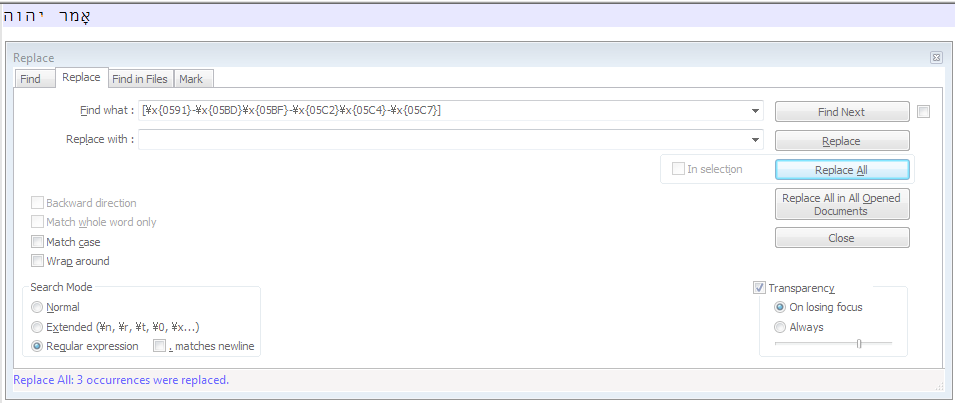
I need to remove Unicode characters in a given range from the selected text. The Unicode characters I want to remove are U+0591-U+05BD, U+05BF-U+05C2, and U+05C4-U+05C7.
I found a way to remove the Hebrew vowels from a Unicode text string using the REGEXREPLACE function in Google Sheets (thank you GitHub). E.g:
=REGEXREPLACE(B1,"[(\x{0591}-\x{05BD})OR(\x{05BF}-\x{05C2})OR(\x{05C4}-\x{05C7})]","")
where cell B1 contains the original Hebrew text with vowels, and the function outputs the identical text with the vowels removed. The Unicode range used there permits me to leave two characters that need to remain (U+05BE and U+05C3).
Using that method, I can copy a Hebrew text string, e.g., אָמַר יְהוָה, paste it into my Google Sheet, and then copy the output, אמר יהוה, and paste it over the original text. This is much slower than a macro in Word would be (there are hundreds of these Hebrew text strings that need to be fixed). The majority of the document is in English, with snippets of Hebrew, so I don't need a solution for converting a whole document.
A bit of searching suggests to me that a similar RegEx replace function exists for Word VBA, but I don't have sufficient programming knowledge to adapt this to my own needs.