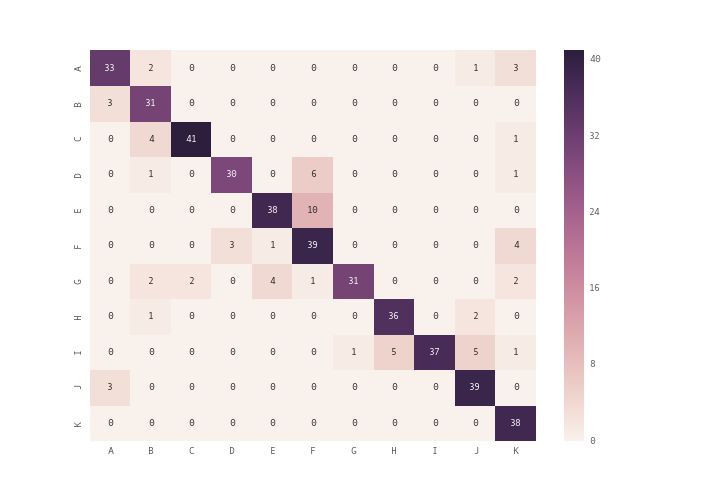
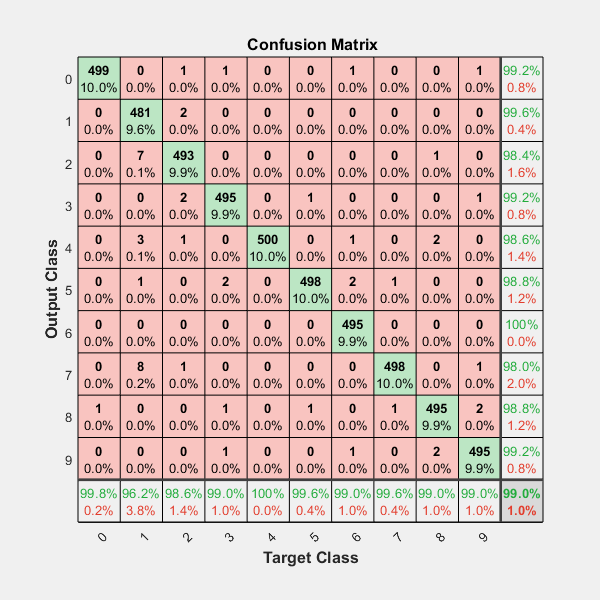
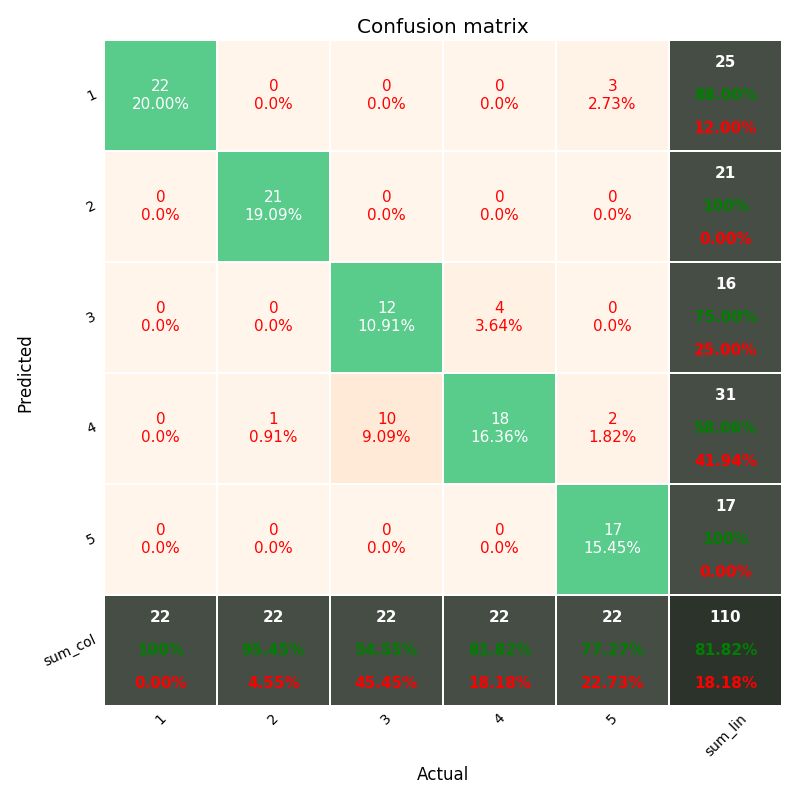
I am using scikit-learn for classification of text documents(22000) to 100 classes. I use scikit-learn's confusion matrix method for computing the confusion matrix.
model1 = LogisticRegression()
model1 = model1.fit(matrix, labels)
pred = model1.predict(test_matrix)
cm=metrics.confusion_matrix(test_labels,pred)
print(cm)
plt.imshow(cm, cmap='binary')
This is how my confusion matrix looks like:
[[3962 325 0 ..., 0 0 0]
[ 250 2765 0 ..., 0 0 0]
[ 2 8 17 ..., 0 0 0]
...,
[ 1 6 0 ..., 5 0 0]
[ 1 1 0 ..., 0 0 0]
[ 9 0 0 ..., 0 0 9]]
However, I do not receive a clear or legible plot. Is there a better way to do this?