I am training Tensorflow Object detection on Windows 10using faster_rcnn_inception_v2_coco as pretrained model. I'm on Windows 10, with tensorflow-gpu 1.6 on NVIDIA GeForce GTX 1080, CUDA 9.0 and CUDNN 7.0.
My dataset contain only one object, "Pistol", and 3000 images (2700 train set, 300 test set). The size of the images are from ~100x200 to ~800x600.
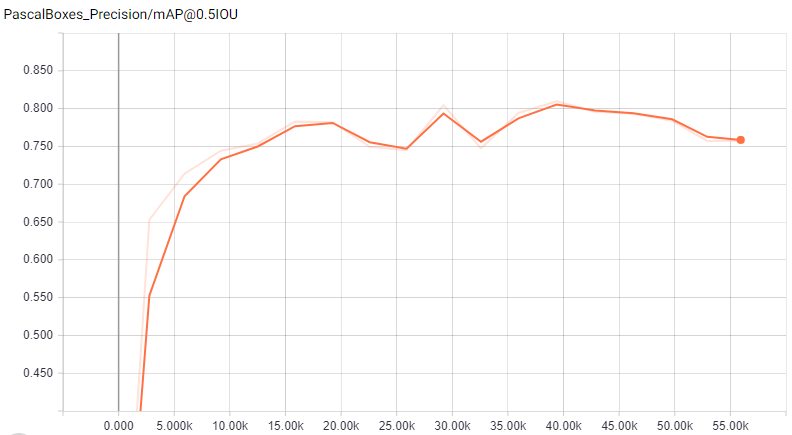
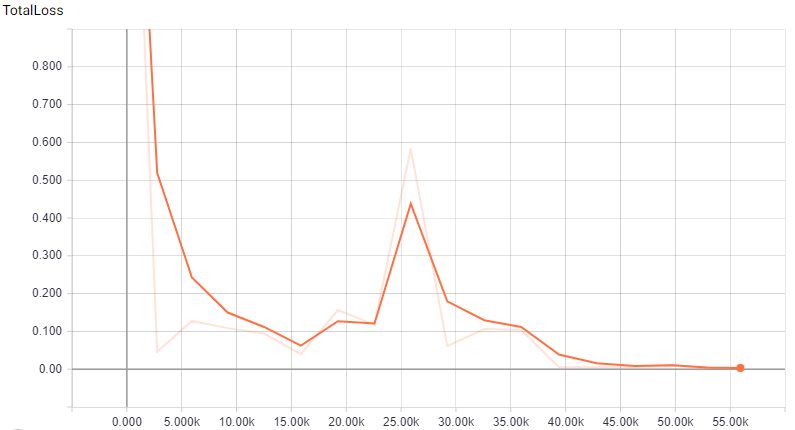
I trained this model for 55k iterations, where the mAP was ~0.8 and the TotalLoss seems converged to 0.001. But however, seeing the evaluation, that there are a lot of multiple bounding boxes on the same detected object (e.g. this and this), and lot of false positives (house detected as a pistol). For example, in this photo taked by me (blur filter was applied later), the model detect a person and a car as pistols, as well as the correct detection.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The dataset is uploaded here, together with the tfrecords and the label map. I used this config file, where the only things that I changed are: num_classes to 1, the fine_tune_checkpoint, input_path and label_map_path for train and eval, and num_examples. Since I thought that the multiple boxes are a non-max-suppression problem, I changed the score_threshold (line 73) from 0 to 0.01 and the iou_threshold (line 74) from 1 to 0.6. With the standard values the outcome was much worse than this.
What can I do to have a good detection? What should I change? Maybe I miss something about parameters tuning...
Thanks