I'm trying to run an xgboost regressor model on a dataset without any missing data.
# Run GBM on training dataset
# Create xgboost object
pts_xgb = xgb.XGBRegressor(objective="reg:squarederror", missing=None, seed=42)
# Fit xgboost onto data
pts_xgb.fit(X_train
,y_train
,verbose=True
,early_stopping_rounds=10
,eval_metric='rmse'
,eval_set=[(X_test,y_test)])
The model creation seems to work fine, and I confirmed that X_train and y_train have no null values, using the following:
print(X_train.isnull().values.sum()) # prints 0
print(y_train.isnull().values.sum()) # prints 0
But when I run the following code, I get the below error.
Code:
pts_xgb.score(X_train,y_train)
Error:
---------------------------------------------------------------------------
XGBoostError Traceback (most recent call last)
<ipython-input-37-39b223d418b2> in <module>
----> 1 pts_xgb.score(X_train_test,y_train_test)
/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/sklearn/base.py in score(self, X, y, sample_weight)
551
552 from .metrics import r2_score
--> 553 y_pred = self.predict(X)
554 return r2_score(y, y_pred, sample_weight=sample_weight)
555
/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/xgboost/sklearn.py in predict(self, X, output_margin, ntree_limit, validate_features, base_margin, iteration_range)
818 if self._can_use_inplace_predict():
819 try:
--> 820 predts = self.get_booster().inplace_predict(
821 data=X,
822 iteration_range=iteration_range,
/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/xgboost/core.py in inplace_predict(self, data, iteration_range, predict_type, missing, validate_features, base_margin, strict_shape)
1844 from .data import _maybe_np_slice
1845 data = _maybe_np_slice(data, data.dtype)
-> 1846 _check_call(
1847 _LIB.XGBoosterPredictFromDense(
1848 self.handle,
/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/xgboost/core.py in _check_call(ret)
208 """
209 if ret != 0:
--> 210 raise XGBoostError(py_str(_LIB.XGBGetLastError()))
211
212
XGBoostError: [09:18:58] /Users/travis/build/dmlc/xgboost/src/c_api/c_api_utils.h:157: Invalid missing value: null
Stack trace:
[bt] (0) 1 libxgboost.dylib 0x000000011e4e7064 dmlc::LogMessageFatal::~LogMessageFatal() + 116
[bt] (1) 2 libxgboost.dylib 0x000000011e4d9afc xgboost::GetMissing(xgboost::Json const&) + 268
[bt] (2) 3 libxgboost.dylib 0x000000011e4e0a13 void InplacePredictImpl<xgboost::data::ArrayAdapter>(std::__1::shared_ptr<xgboost::data::ArrayAdapter>, std::__1::shared_ptr<xgboost::DMatrix>, char const*, xgboost::Learner*, unsigned long, unsigned long, unsigned long long const**, unsigned long long*, float const**) + 531
[bt] (3) 4 libxgboost.dylib 0x000000011e4e04d3 XGBoosterPredictFromDense + 339
[bt] (4) 5 libffi.dylib 0x00007fff2dc7f8e5 ffi_call_unix64 + 85
Same error occurs if I try to run pts_xgb.predict(X_train)
Edit: this is not an issue with any missing/null values in either X_train or y_train. I got the same error when using the following dataset which is much smaller than my actual dataset (see below):
X_train: 1
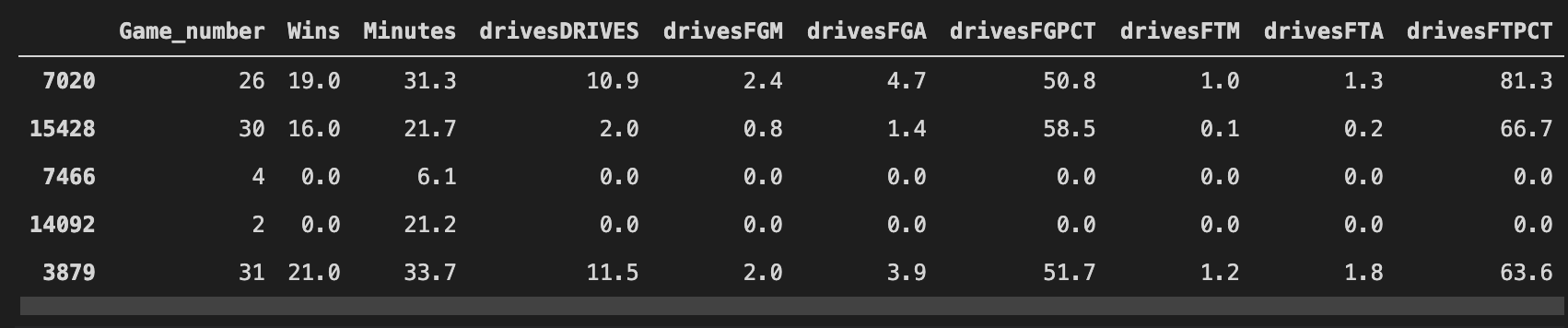{kind=link}
y_train: 2
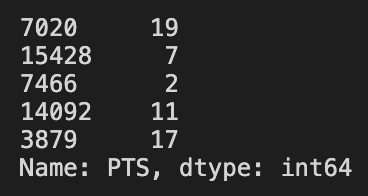{kind=link}
Anyone have any idea why this may be happening? I couldn't find any other forums that discuss the same issue.