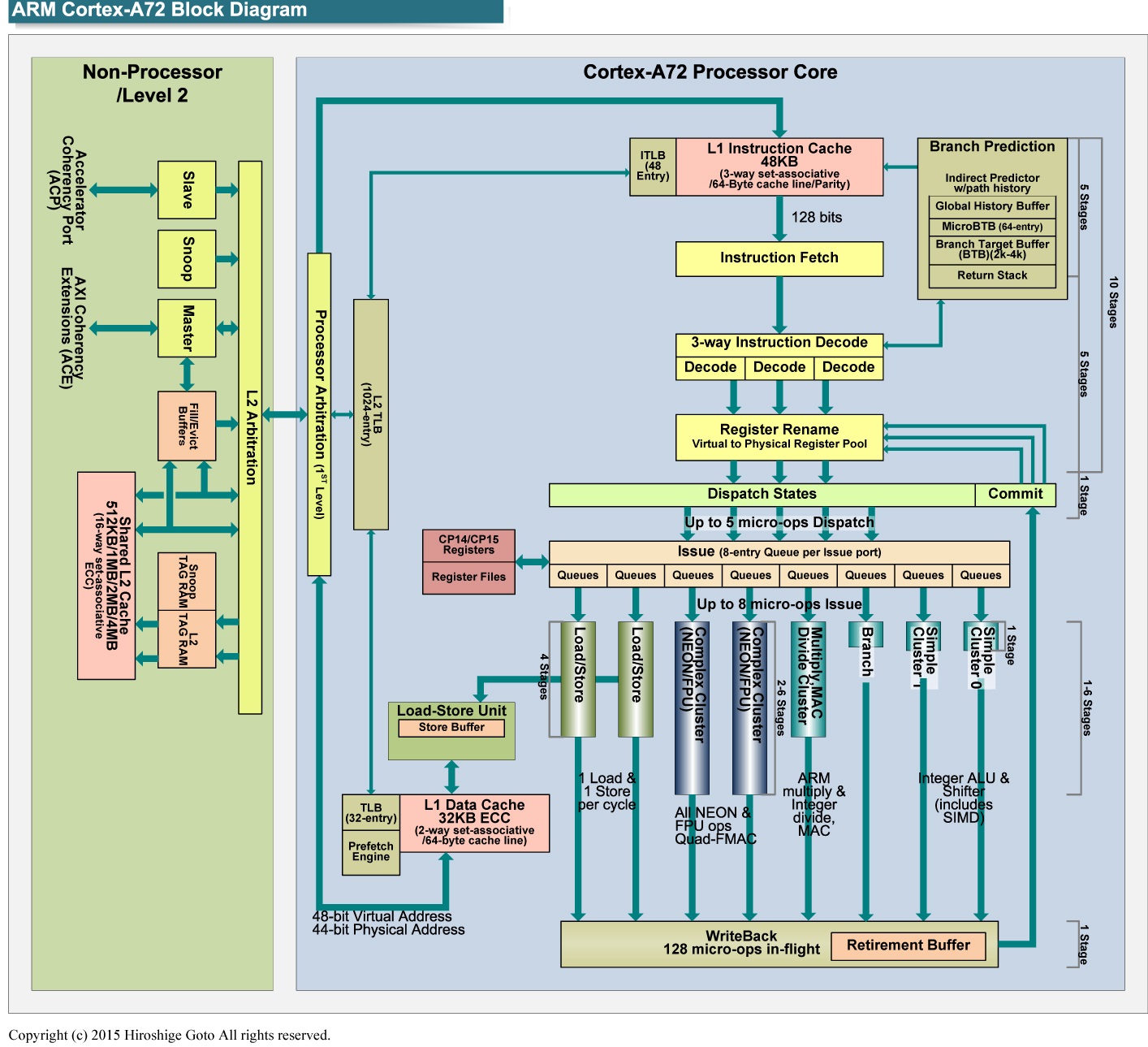
Consider the following code, running on an ARM Cortex-A72 processor (optimization guide here). I have included what I expect are resource pressures for each execution port:
| Instruction | B | I0 | I1 | M | L | S | F0 | F1 |
|---|---|---|---|---|---|---|---|---|
.LBB0_1: |
||||||||
ldr q3, [x1], #16 |
0.5 | 0.5 | 1 | |||||
ldr q4, [x2], #16 |
0.5 | 0.5 | 1 | |||||
add x8, x8, #4 |
0.5 | 0.5 | ||||||
cmp x8, #508 |
0.5 | 0.5 | ||||||
mul v5.4s, v3.4s, v4.4s |
2 | |||||||
mul v5.4s, v5.4s, v0.4s |
2 | |||||||
smull v6.2d, v5.2s, v1.2s |
1 | |||||||
smull2 v5.2d, v5.4s, v2.4s |
1 | |||||||
smlal v6.2d, v3.2s, v4.2s |
1 | |||||||
smlal2 v5.2d, v3.4s, v4.4s |
1 | |||||||
uzp2 v3.4s, v6.4s, v5.4s |
1 | |||||||
str q3, [x0], #16 |
0.5 | 0.5 | 1 | |||||
b.lo .LBB0_1 |
1 | |||||||
| Total port pressure | 1 | 2.5 | 2.5 | 0 | 2 | 1 | 8 | 1 |
Although uzp2 could run on either the F0 or F1 ports, I chose to attribute it entirely to F1 due to high pressure on F0 and zero pressure on F1 other than this instruction.
There are no dependencies between loop iterations, other than the loop counter and array pointers; and these should be resolved very quickly, compared to the time taken for the rest of the loop body.
Thus, my intuition is that this code should be throughput limited, and considering the worst pressure is on F0, run in 8 cycles per iteration (unless it hits a decoding bottleneck or cache misses). The latter is unlikely given the streaming access pattern, and the fact that arrays comfortably fit in L1 cache. As for the former, considering the constraints listed on section 4.1 of the optimization manual, I project that the loop body is decodable in only 8 cycles.
Yet microbenchmarking indicates that each iteration of the loop body takes 12.5 cycles on average. If no other plausible explanation exists, I may edit the question including further details about how I benchmarked this code, but I'm fairly certain the difference can't be attributed to benchmarking artifacts alone. Also, I have tried to increase the number of iterations to see if performance improved towards an asymptotic limit due to startup/cool-down effects, but it appears to have done so already for the selected value of 128 iterations displayed above.
Manually unrolling the loop to include two calculations per iteration decreased performance to 13 cycles; however, note that this would also duplicate the number of load and store instructions. Interestingly, if the doubled loads and stores are instead replaced by single LD1/ST1 instructions (two-register format) (e.g. ld1 { v3.4s, v4.4s }, [x1], #32) then performance improves to 11.75 cycles per iteration. Further unrolling the loop to four calculations per iteration, while using the four-register format of LD1/ST1, improves performance to 11.25 cycles per iteration.
In spite of the improvements, the performance is still far away from the 8 cycles per iteration that I expected from looking at resource pressures alone. Even if the CPU made a bad scheduling call and issued uzp2 to F0, revising the resource pressure table would indicate 9 cycles per iteration, still far from actual measurements. So, what's causing this code to run so much slower than expected? What kind of effects am I missing in my analysis?
EDIT: As promised, some more benchmarking details. I run the loop 3 times for warmup, 10 times for say n = 512, and then 10 times for n = 256. I take the minimum cycle count for the n = 512 runs and subtract from the minimum for n = 256. The difference should give me how many cycles it takes to run for n = 256, while canceling out the fixed setup cost (code not shown). In addition, this should ensure all data is in the L1 I and D cache. Measurements are taken by reading the cycle counter (pmccntr_el0) directly. Any overhead should be canceled out by the measurement strategy above.
{kind=link}
-mllvm -align-all-blocks=4option to clang when compiling. Thus, any branch targets (not only function boundaries) should be aligned to 16 bytes. – Graphicsx0's memory doesn't overlap with others? I can't think of any other reason than "A72 just sucks" (and it does) How about benchmarking on other chips? (Different A72 or A75) – Surrealism