Hello everyone I am getting my hands dirty with gRPC and protocol buffers and have came across an article which has mentioned that the binary protobuf file for a message is 5 times smaller than Json counterpart but in that article it is mentioned that this level of compression can only be achieved if transmitting via gRPC. This particular comment "compression possible when transmitting via gRPC", I cant seem to understand cause i had an understanding that protocol buffer is a serialization format which can work irrespective of gRPC or is this understanding flawed? what does this means? here is the link to the article and the screen shot.
https://www.datascienceblog.net/post/programming/essential-protobuf-guide-python/
can protocol buffer be used without gRPC?
Asked Answered
You are correct - Protocol buffers "provide a serialization format for packets of typed, structured data that are up to a few megabytes in size" and has many uses (e.g. serialising data to disk, network transmission, passing data between applications etc).
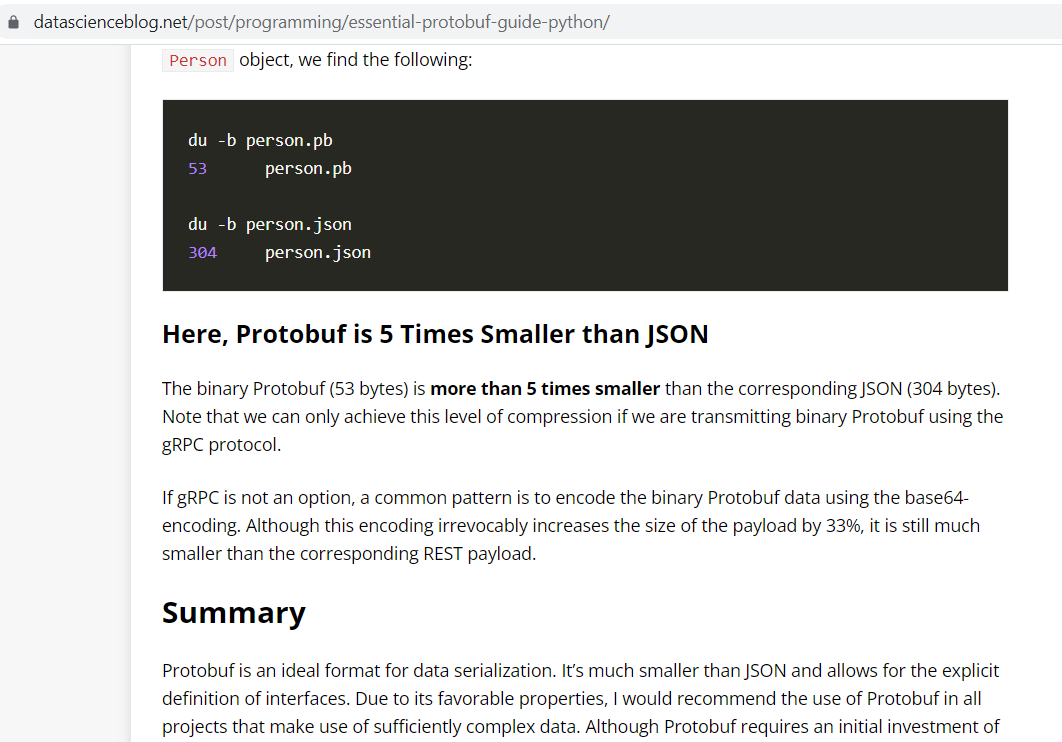
The article you reference is somewhat misleading when it says
we can only achieve this level of compression if we are transmitting binary Protobuf using the gRPC protocol
The reasoning behind the statement becomes a bit clearer when you consider the following paragraph:
If gRPC is not an option, a common pattern is to encode the binary Protobuf data using the base64-encoding. Although this encoding irrevocably increases the size of the payload by 33%, it is still much smaller than the corresponding REST payload.
So this appears to be focusing on transmitting data over HTTP which is a text based protocol (HTTP/2 changes this somewhat).
Because Profobuf is a binary format it is often encoded before being transmitted via HTTP (technically it could be transferred in a binary format using something like application/octet-stream). The article mentions base64-encoding and using this this increases it's size.
If you are not using HTTP (e.g. writing to disk, direct TCP/IP link, Websockets, MQTT etc) then this does not apply.
Having said that I believe that the example may be overstating the benefits of Protobuf a little because a lot of HTTP traffic is compressed (this article reported a 9% difference in their test).
"Because Profobuf is a binary format you need to encode the data before it can be transmitted via HTTP (the article mentions base64-encoding) and doing this increases it's size." I feel like this statement is false. I did some searching around StackOverflow, like this question, and they all seem to contradict this statement. I believe you are confusing what is common, with what is possible. It may be common to encode binary data, but not required. Header is text, but not necessarily the payload. –
Characterization
@GregCobb you are correct; it is possible to send binary data via HTTP (and this happens frequently, e.g. the images on this page). Protobuf data could be sent as an
application/octet-stream but in this case the article specifically mentioned base-64 encoding. –
Titania I agree with Brits' answer.
Some separate points. It's not quite accurate to talk about GPB compressing data; it merely goes some way to minimally encode data (e.g. integers). If you send a GPB message that has 10 strings all the same, it won't compress that down in the same way you might expect zip to.
GPB is not the most efficent encoder of data out there. ASN.1 uPER is even better, being able to exploit knowledge that can be put into an ASN.1 schema that cannot be expressed in a GPB schema .proto file. For example, in ASN.1 you can constrain the value of an integer to, say, 1000..1003. In ASN.1 uPER that's 2 bits (there are 4 possible values). In GPB, that's two bytes of encoded data at least.
© 2022 - 2025 — McMap. All rights reserved.