I have what I hope is an easy question. I'm trying to use iTextSharp to modify some PDF files, however it seems that the XMP metadata that iTextSharp puts at the end of the files is ruining the layout of the PDF files (and I'm not very conversant in the PDF format to understand at all why).

 You can see from the two images above that the document appears to have been rotated. From looking at the PDF files as binary differences however, the only thing different appears to be some XMP metadata at the end of the files
You can see from the two images above that the document appears to have been rotated. From looking at the PDF files as binary differences however, the only thing different appears to be some XMP metadata at the end of the files
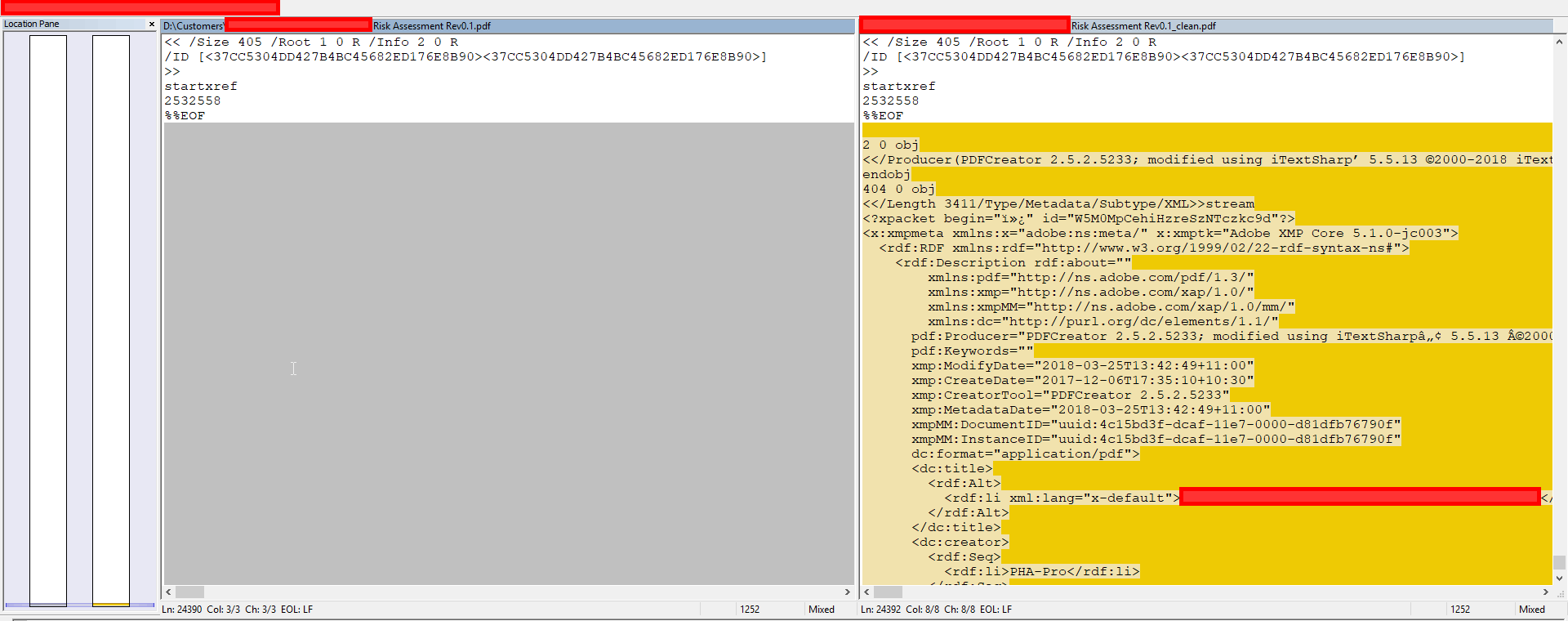
I've tried opening the files in several PDF viewers (Sumatra PDF, Edge Browser and Adobe Acrobat) and all show the same weirdness.
I guess I have two questions: a) How can the PDF file be so altered from just having XMP meteadata at the end of the file? b) How can I make iTextSharp not produce this output? (iTextSharp only seems to do this when I Add/Edit content, and not if I just strip out Javascript or similar)
<EDIT 1>
The code that I'm using for the iTextSharp is the PdfContentStreamEditor (verbatim) from the post here: https://mcmap.net/q/1469305/-removing-watermark-from-pdf-itextsharp
</EDIT 1>
<EDIT 2>
Ok.. it seems that it's not the XMP Metadata. I got rid of that by using:
pdfStamper.XmpMetadata = new byte[0];
However there is still a bunch of extra data placed at the end of the file
2 0 obj
<</Producer(PDFCreator 2.5.2.5233; modified using iTextSharp’ 5.5.13 ©2000-2018 iText Group NV \(AGPL-version\))/CreationDate(D:20171206173510+10'30')/ModDate(D:20180325144710+11'00')/Title(þÿ
endobj
404 0 obj
<</Length 0/Type/Metadata/Subtype/XML>>stream
endstream
endobj
405 0 obj
<</Length 3638/Filter/FlateDecode>>stream
xœÍZmÅ/6ÒZ2ÁÆ€
....
</EDIT 2>


PdfContentStreamEditorclass. To verify I'd need the PDF in question, though. – Ivelisseivens