I have a BlockBlob in Premium Azure Storage. It's a 500mb zip file containing around 280 million phone numbers in CSV format.
I've created a Pipeline in ADF to unzip this and copy the entries into Cosmos DB SQL API, but it took 40 hours to complete. The goal is to update the DB nightly with a diff in the information.
My Storage Account and Cosmos DB are located in the same region. The Cosmos DB partition key is the area code and that seems to distribute well.
Currently, at 20,000 RU's I've scaled a few time, but the portal keeps telling me to scale more. They are suggesting 106,000 RU's which is $6K a month. Any ideas on practical ways I can speed this up?
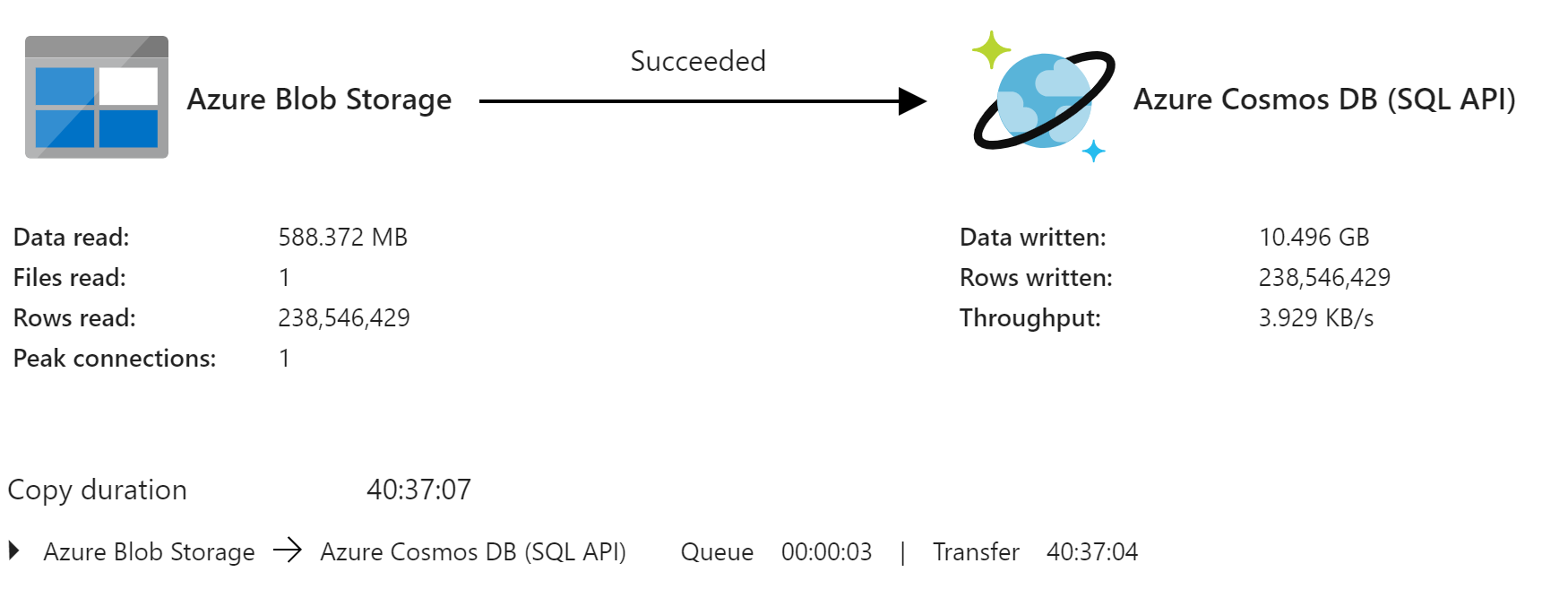
-- Update.
I've tried importing the unzipped file, but it doesn't appear any faster. Slower in fact, despite reporting more peak connections.
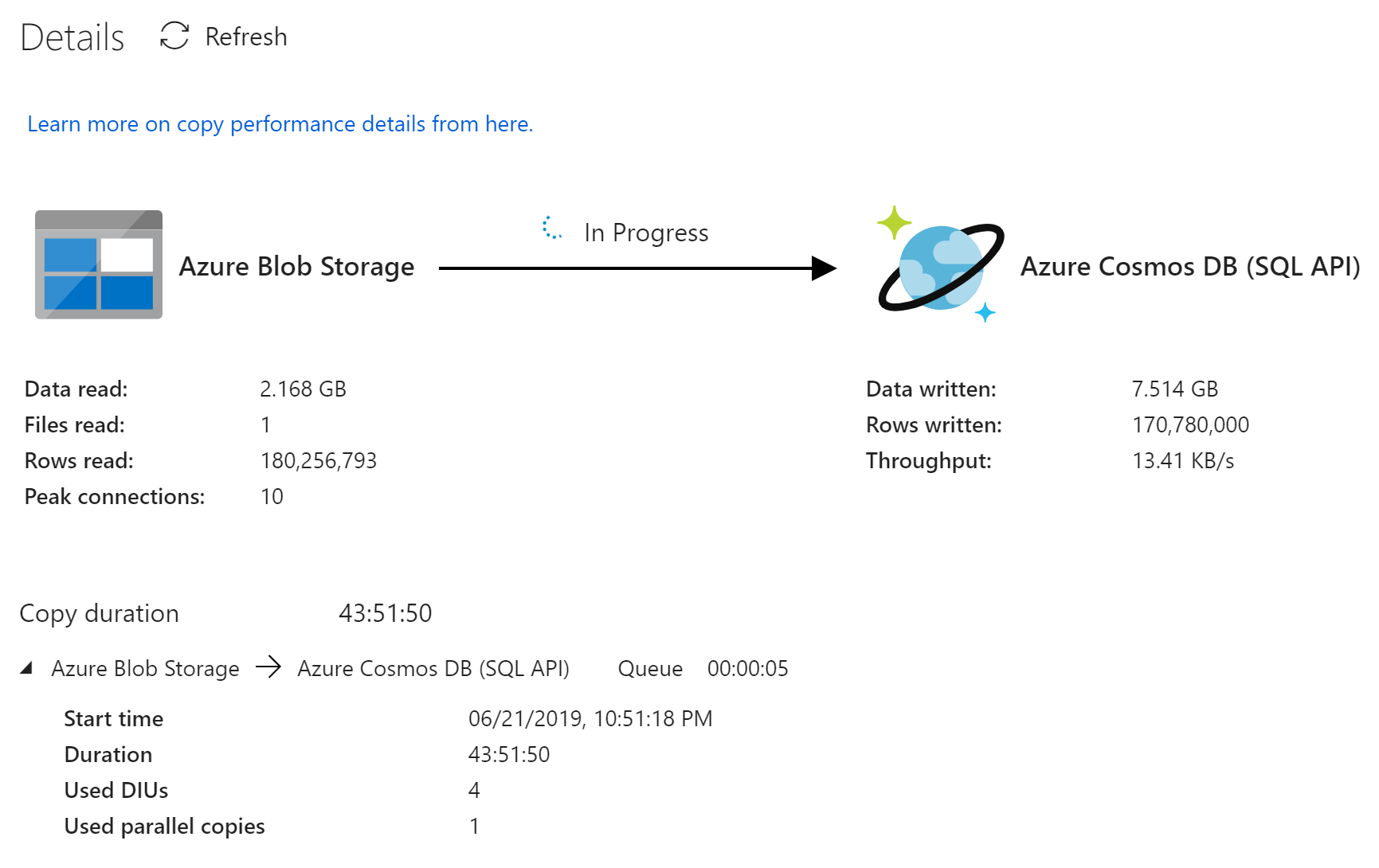
I'm now trying to dynamically scale up/down the RU's to a really high number when it's time to start the transfer. Still playing with numbers. Not sure the formula to determine the number of RUs I need to transfer this 10.5GB in X minutes.