I am running into some problems in (Py)Spark on EMR (release 5.32.0). Approximately a year ago I ran the same program on an EMR cluster (I think the release must have been 5.29.0). Then I was able to configure my PySpark program using spark-submit arguments properly. However, now I am running the same/similar code, but the spark-submit arguments do not seem to have any effect.
My cluster configuration:
- master node: 8 vCore, 32 GiB memory, EBS only storage EBS Storage:128 GiB
- slave nodes: 10 x 16 vCore, 64 GiB memory, EBS only storage EBS Storage:256 GiB
I run the program with the following spark-submit arguments:
spark-submit --master yarn --conf "spark.executor.cores=3" --conf "spark.executor.instances=40" --conf "spark.executor.memory=8g" --conf "spark.driver.memory=8g" --conf "spark.driver.maxResultSize=8g" --conf "spark.dynamicAllocation.enabled=false" --conf "spark.default.parallelism=480" update_from_text_context.py
I did not change anything in the default configurations on the cluster.
Below a screenshot of the Spark UI, which is indicating only 10 executors, whereas I expect to have 40 executors available...
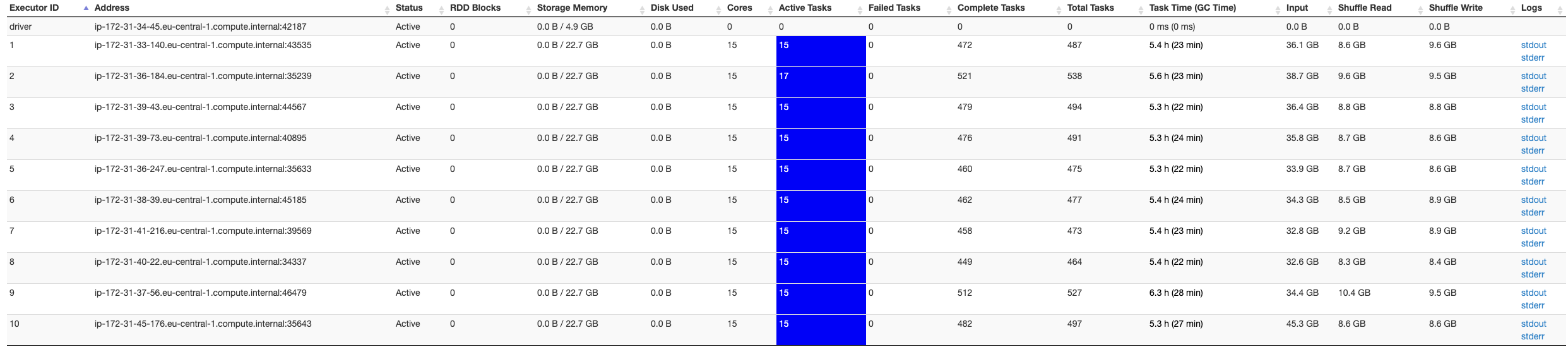
I tried different spark-submit arguments in order to make sure that the error was unrelated to Apache Spark: setting executor instances does not change the executors. I tried a lot of things, and nothing seems to help.
I am a little lost here, could someone help?
UPDATE:
I ran the same code on EMR release label 5.29.0, and there the conf settings in the spark-submit argument seems to have effect:

Why is this happening?