I have a CSV and I want to check if it has all the data it should have. But it looks like ZWNBSP appears at the beginning of the 1st column name in the 1st string.
My simplified code is
@Test
void parseCsvTest() throws Exception {
Configuration.holdBrowserOpen = true;
ClassLoader classLoader = getClass().getClassLoader();
try (
InputStream inputStream = classLoader.getResourceAsStream("files/csv_example.csv");
CSVReader reader = new CSVReader(new InputStreamReader(inputStream))
) {
List<String[]> content = reader.readAll();
var csvStrings0line = content.get(0);
var csv1stElement = csvStrings0line[0];
var csv1stElementShouldBe = "Timestamp";
assertEquals(csv1stElementShouldBe,csv1stElement);
My CSV contains
"Timestamp","Source","EventName","CountryId","Platform","AppVersion","DeviceType","OsVersion"
"2022-05-02T14:56:59.536987Z","courierapp","order_delivered_sent","643","ios","3.11.0","iPhone 11","15.4.1"
"2022-05-02T14:57:35.849328Z","courierapp","order_delivered_sent","643","ios","3.11.0","iPhone 8","15.3.1"
My test fails with
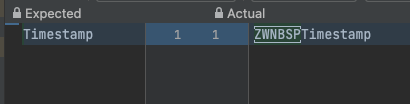
expected: <Timestamp> but was: <Timestamp>
Expected :Timestamp
Actual :Timestamp
<Click to see difference>
Clicking on the see difference shows that there is a ZWNBSP at the beginning of the Actual text.
Copypasting my text to the online tool for displaying non-printable unicode characters https://www.soscisurvey.de/tools/view-chars.php shows only CR LF at the ends of the lines, no ZWNBSPs.
But where does it come from?
{kind=link}