I have implemented a simple Kafka Dead letter record processor.
It works perfectly when using records produced from the Console producer.
However I find that our Kafka Streams applications do not guarantee that producing records to the sink topics that the offsets will be incremented by 1 for each record produced.
Dead Letter Processor Background:
I have a scenario where records may be received before all data required to process it is published. When records are not matched for processing by the streams app they are move to a Dead letter topic instead of continue to flow down stream. When new data is published we dump the latest messages from the Dead letter topic back in to the stream application's source topic for reprocessing with the new data.
The Dead Letter processor:
- At the start of the run application records the ending offsets of each partition
- The ending offsets marks the point to stop processing records for a given Dead Letter topic to avoid infinite loop if reprocessed records return to Dead Letter topic.
- Application resumes from the last Offsets produced by the previous run via consumer groups.
- Application is using transactions and
KafkaProducer#sendOffsetsToTransactionto commit the last produced offsets.
To track when all records in my range are processed for a topic's partition my service compares its last produced offset from the producer to the the consumers saved map of ending offsets. When we reach the ending offset the consumer pauses that partition via KafkaConsumer#pause and when all partitions are paused (meaning they reached the saved Ending offset)then calls it exits.
The Kafka Consumer API States:
Offsets and Consumer Position Kafka maintains a numerical offset for each record in a partition. This offset acts as a unique identifier of a record within that partition, and also denotes the position of the consumer in the partition. For example, a consumer which is at position 5 has consumed records with offsets 0 through 4 and will next receive the record with offset 5.
The Kafka Producer API references the next offset is always +1 as well.
Sends a list of specified offsets to the consumer group coordinator, and also marks those offsets as part of the current transaction. These offsets will be considered committed only if the transaction is committed successfully. The committed offset should be the next message your application will consume, i.e. lastProcessedMessageOffset + 1.
But you can clearly see in my debugger that the records consumed for a single partition are anything but incremented 1 at a time...
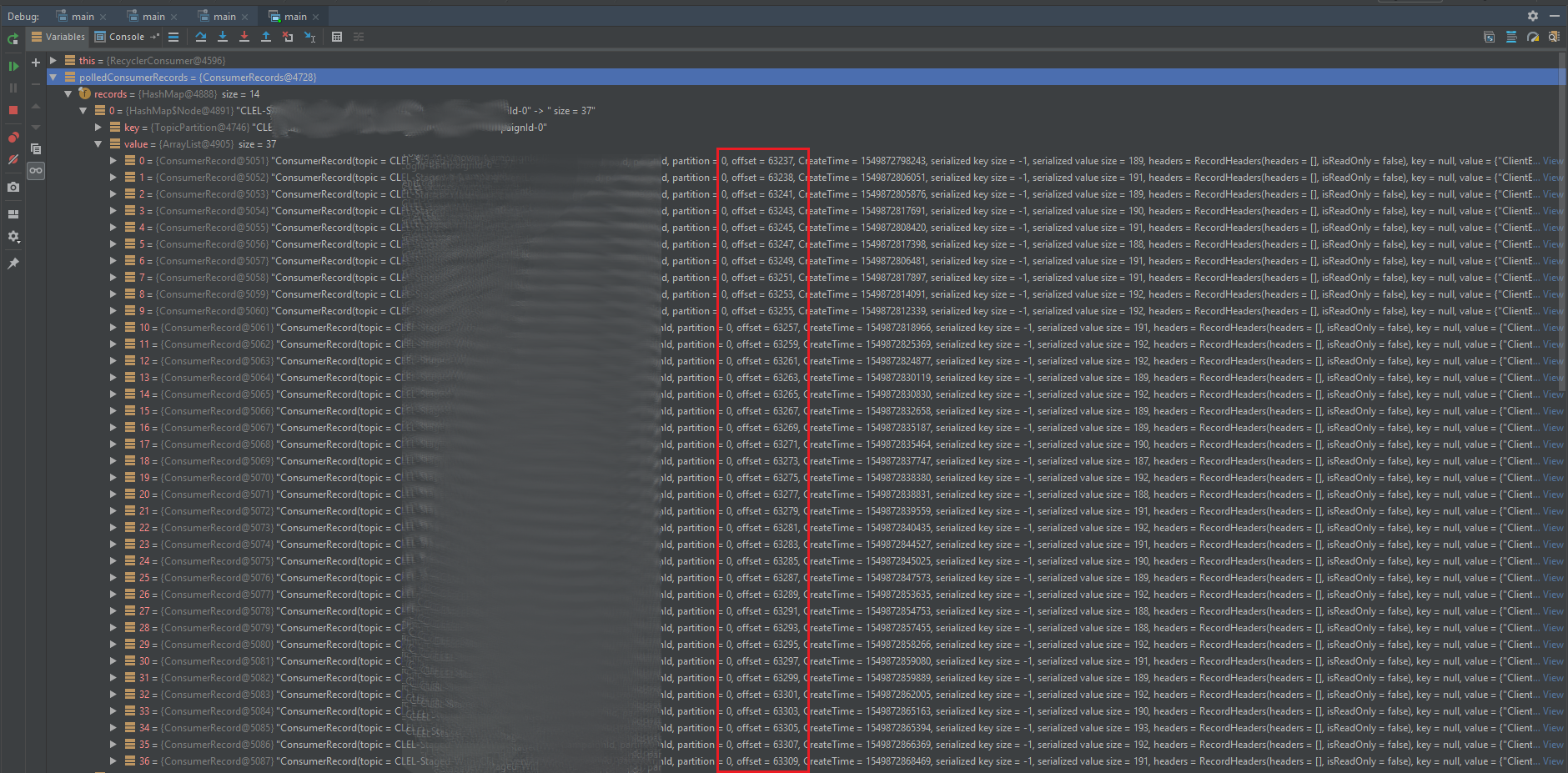
I thought maybe this was a Kafka configuration issue such as max.message.bytes but none really made sense.
Then I thought perhaps it is from joining but didn't see any way that would change the way the producer would function.
Not sure if it is relevant or not but all of our Kafka applications are using Avro and Schema Registry...
Should the offsets always increment by 1 regardless of method of producing or is it possible that using Kafka streams API does not offer the same guarantees as the normal Producer Consumer clients?
Is there just something entirely that I am missing?