Im having a problem with removing non-utf8 characters from string, which are not displaying properly. Characters are like this 0x97 0x61 0x6C 0x6F (hex representation)
What is the best way to remove them? Regular expression or something else ?
Im having a problem with removing non-utf8 characters from string, which are not displaying properly. Characters are like this 0x97 0x61 0x6C 0x6F (hex representation)
What is the best way to remove them? Regular expression or something else ?
Using a regex approach:
$regex = <<<'END'
/
(
(?: [\x00-\x7F] # single-byte sequences 0xxxxxxx
| [\xC0-\xDF][\x80-\xBF] # double-byte sequences 110xxxxx 10xxxxxx
| [\xE0-\xEF][\x80-\xBF]{2} # triple-byte sequences 1110xxxx 10xxxxxx * 2
| [\xF0-\xF7][\x80-\xBF]{3} # quadruple-byte sequence 11110xxx 10xxxxxx * 3
){1,100} # ...one or more times
)
| . # anything else
/x
END;
preg_replace($regex, '$1', $text);
It searches for UTF-8 sequences, and captures those into group 1. It also matches single bytes that could not be identified as part of a UTF-8 sequence, but does not capture those. Replacement is whatever was captured into group 1. This effectively removes all invalid bytes.
It is possible to repair the string, by encoding the invalid bytes as UTF-8 characters. But if the errors are random, this could leave some strange symbols.
$regex = <<<'END'
/
(
(?: [\x00-\x7F] # single-byte sequences 0xxxxxxx
| [\xC0-\xDF][\x80-\xBF] # double-byte sequences 110xxxxx 10xxxxxx
| [\xE0-\xEF][\x80-\xBF]{2} # triple-byte sequences 1110xxxx 10xxxxxx * 2
| [\xF0-\xF7][\x80-\xBF]{3} # quadruple-byte sequence 11110xxx 10xxxxxx * 3
){1,100} # ...one or more times
)
| ( [\x80-\xBF] ) # invalid byte in range 10000000 - 10111111
| ( [\xC0-\xFF] ) # invalid byte in range 11000000 - 11111111
/x
END;
function utf8replacer($captures) {
if ($captures[1] != "") {
// Valid byte sequence. Return unmodified.
return $captures[1];
}
elseif ($captures[2] != "") {
// Invalid byte of the form 10xxxxxx.
// Encode as 11000010 10xxxxxx.
return "\xC2".$captures[2];
}
else {
// Invalid byte of the form 11xxxxxx.
// Encode as 11000011 10xxxxxx.
return "\xC3".chr(ord($captures[3])-64);
}
}
preg_replace_callback($regex, "utf8replacer", $text);
EDIT:
!empty(x) will match non-empty values ("0" is considered empty).x != "" will match non-empty values, including "0".x !== "" will match anything except "".x != "" seem the best one to use in this case.
I have also sped up the match a little. Instead of matching each character separately, it matches sequences of valid UTF-8 characters.
If you apply utf8_encode() to an already UTF8 string it will return a garbled UTF8 output.
I made a function that addresses all this issues. It´s called Encoding::toUTF8().
You dont need to know what the encoding of your strings is. It can be Latin1 (ISO8859-1), Windows-1252 or UTF8, or the string can have a mix of them. Encoding::toUTF8() will convert everything to UTF8.
I did it because a service was giving me a feed of data all messed up, mixing those encodings in the same string.
Usage:
require_once('Encoding.php');
use \ForceUTF8\Encoding; // It's namespaced now.
$utf8_string = Encoding::toUTF8($mixed_string);
$latin1_string = Encoding::toLatin1($mixed_string);
I've included another function, Encoding::fixUTF8(), which will fix every UTF8 string that looks garbled product of having been encoded into UTF8 multiple times.
Usage:
require_once('Encoding.php');
use \ForceUTF8\Encoding; // It's namespaced now.
$utf8_string = Encoding::fixUTF8($garbled_utf8_string);
Examples:
echo Encoding::fixUTF8("Fédération Camerounaise de Football");
echo Encoding::fixUTF8("Fédération Camerounaise de Football");
echo Encoding::fixUTF8("FÃÂédÃÂération Camerounaise de Football");
echo Encoding::fixUTF8("Fédération Camerounaise de Football");
will output:
Fédération Camerounaise de Football
Fédération Camerounaise de Football
Fédération Camerounaise de Football
Fédération Camerounaise de Football
Download:
231 Vía La Paz -- Returns with the same í –
Wideman Using a regex approach:
$regex = <<<'END'
/
(
(?: [\x00-\x7F] # single-byte sequences 0xxxxxxx
| [\xC0-\xDF][\x80-\xBF] # double-byte sequences 110xxxxx 10xxxxxx
| [\xE0-\xEF][\x80-\xBF]{2} # triple-byte sequences 1110xxxx 10xxxxxx * 2
| [\xF0-\xF7][\x80-\xBF]{3} # quadruple-byte sequence 11110xxx 10xxxxxx * 3
){1,100} # ...one or more times
)
| . # anything else
/x
END;
preg_replace($regex, '$1', $text);
It searches for UTF-8 sequences, and captures those into group 1. It also matches single bytes that could not be identified as part of a UTF-8 sequence, but does not capture those. Replacement is whatever was captured into group 1. This effectively removes all invalid bytes.
It is possible to repair the string, by encoding the invalid bytes as UTF-8 characters. But if the errors are random, this could leave some strange symbols.
$regex = <<<'END'
/
(
(?: [\x00-\x7F] # single-byte sequences 0xxxxxxx
| [\xC0-\xDF][\x80-\xBF] # double-byte sequences 110xxxxx 10xxxxxx
| [\xE0-\xEF][\x80-\xBF]{2} # triple-byte sequences 1110xxxx 10xxxxxx * 2
| [\xF0-\xF7][\x80-\xBF]{3} # quadruple-byte sequence 11110xxx 10xxxxxx * 3
){1,100} # ...one or more times
)
| ( [\x80-\xBF] ) # invalid byte in range 10000000 - 10111111
| ( [\xC0-\xFF] ) # invalid byte in range 11000000 - 11111111
/x
END;
function utf8replacer($captures) {
if ($captures[1] != "") {
// Valid byte sequence. Return unmodified.
return $captures[1];
}
elseif ($captures[2] != "") {
// Invalid byte of the form 10xxxxxx.
// Encode as 11000010 10xxxxxx.
return "\xC2".$captures[2];
}
else {
// Invalid byte of the form 11xxxxxx.
// Encode as 11000011 10xxxxxx.
return "\xC3".chr(ord($captures[3])-64);
}
}
preg_replace_callback($regex, "utf8replacer", $text);
EDIT:
!empty(x) will match non-empty values ("0" is considered empty).x != "" will match non-empty values, including "0".x !== "" will match anything except "".x != "" seem the best one to use in this case.
I have also sped up the match a little. Instead of matching each character separately, it matches sequences of valid UTF-8 characters.
You can use mbstring:
$text = mb_convert_encoding($text, 'UTF-8', 'UTF-8');
...will remove invalid characters.
See: Replacing invalid UTF-8 characters by question marks, mbstring.substitute_character seems ignored
<0x1a> –
Putscher <0x1a>, although not printable character, is a perfectly valid UTF-8 sequence. You might have issues with non-printable characters? Check this: #1177404 –
Clarita ini_set('mbstring.substitute_character', 'none'); otherwise I was getting question marks in the result. –
Eckard "\xFF" then, that's invalid UTF-8 –
Quadruplicate mb_convert_encoding(), as the OP asked (I'm not 100% sure to understand your point?) –
Clarita This function removes all NON ASCII characters, it's useful but not solving the question:
This is my function that always works, regardless of encoding:
function remove_bs($Str) {
$StrArr = str_split($Str); $NewStr = '';
foreach ($StrArr as $Char) {
$CharNo = ord($Char);
if ($CharNo == 163) { $NewStr .= $Char; continue; } // keep £
if ($CharNo > 31 && $CharNo < 127) {
$NewStr .= $Char;
}
}
return $NewStr;
}
How it works:
echo remove_bs('Hello õhowå åare youÆ?'); // Hello how are you?
í character in the address field which IS a valid UTF-8 character see table. The morale: do not trust API error messages :) –
Gina mb_str_split() and mb_ord() to get the correct CharNo. –
Peacetime $text = iconv("UTF-8", "UTF-8//IGNORE", $text);
This is what I am using. Seems to work pretty well. Taken from http://planetozh.com/blog/2005/01/remove-invalid-characters-in-utf-8/
try this:
$string = iconv("UTF-8","UTF-8//IGNORE",$string);
According to the iconv manual, the function will take the first parameter as the input charset, second parameter as the output charset, and the third as the actual input string.
If you set both the input and output charset to UTF-8, and append the //IGNORE flag to the output charset, the function will drop(strip) all characters in the input string that can't be represented by the output charset. Thus, filtering the input string in effect.
//IGNORE doesn't seem to suppress the notice that invalid UTF-8 is present (which, of course, I know about, and want to fix). A highly rated comment in the manual seems to think it has been a bug for some years. –
Pentup iconv. @Pentup Maybe your input data is not from utf-8. Another option is to make a re-conversion to ascii then back to utf-8 again. In my case i did used iconv like $output = iconv("UTF-8//", "ISO-8859-1//IGNORE", $input ); –
Cetane Hi There you can use simple regex
$text = preg_replace('/[\x00-\x1F\x80-\xFF]/', '', $text);
It would truncate all non UTF-8 characters from string
The text may contain non-utf8 character. Try to do first:
$nonutf8 = mb_convert_encoding($nonutf8 , 'UTF-8', 'UTF-8');
You can read more about it here: http://php.net/manual/en/function.mb-convert-encoding.php[news][2]
UConverter can be used since PHP 5.5. UConverter is better the choice if you use intl extension and don't use mbstring.
function replace_invalid_byte_sequence($str)
{
return UConverter::transcode($str, 'UTF-8', 'UTF-8');
}
function replace_invalid_byte_sequence2($str)
{
return (new UConverter('UTF-8', 'UTF-8'))->convert($str);
}
htmlspecialchars can be used to remove invalid byte sequence since PHP 5.4. Htmlspecialchars is better than preg_match for handling large size of byte and the accuracy. A lot of the wrong implementation by using regular expression can be seen.
function replace_invalid_byte_sequence3($str)
{
return htmlspecialchars_decode(htmlspecialchars($str, ENT_SUBSTITUTE, 'UTF-8'));
}
Welcome to 2019 and the /u modifier in regex which will handle UTF-8 multibyte chars for you
If you only use mb_convert_encoding($value, 'UTF-8', 'UTF-8') you will still end up with non-printable chars in your string
This method will:
mb_convert_encoding\r, \x00 (NULL-byte) and other control chars with preg_replacefunction utf8_filter(string $value): string{
return preg_replace('/[^[:print:]\n]/u', '', mb_convert_encoding($value, 'UTF-8', 'UTF-8'));
}
[:print:] match all printable chars and \n newlines and strip everything else
You can see the ASCII table below.. The printable chars range from 32 to 127, but newline \n is a part of the control chars which range from 0 to 31 so we have to add newline to the regex /[^[:print:]\n]/u
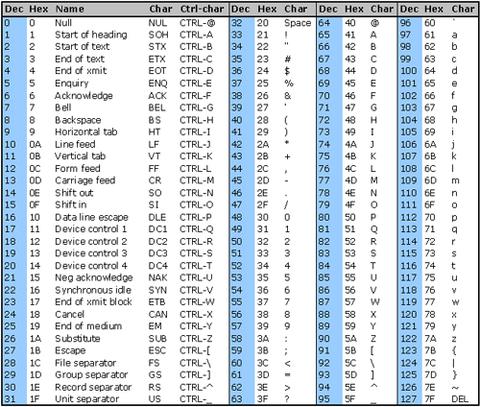
You can try to send strings through the regex with chars outside the printable range like \x7F (DEL), \x1B (Esc) etc. and see how they are stripped
function utf8_filter(string $value): string{
return preg_replace('/[^[:print:]\n]/u', '', mb_convert_encoding($value, 'UTF-8', 'UTF-8'));
}
$arr = [
'Danish chars' => 'Hello from Denmark with æøå',
'Non-printable chars' => "\x7FHello with invalid chars\r \x00"
];
foreach($arr as $k => $v){
echo "$k:\n---------\n";
$len = strlen($v);
echo "$v\n(".$len.")\n";
$strip = utf8_decode(utf8_filter(utf8_encode($v)));
$strip_len = strlen($strip);
echo $strip."\n(".$strip_len.")\n\n";
echo "Chars removed: ".($len - $strip_len)."\n\n\n";
}
php-mbstring is not packed in php by default. –
Huffish \r wth \n? Why not \R? –
Nelan utf8_encode before calling this function makes no sense. If your string is in ISO 8859-1 encoding, that function will make it into UTF-8; if it's anything else - including UTF-8 - it will make it into a garbled string, which will be valid UTF-8. So you end up running the "remove non-printables" regex on the garbled string, and getting a bunch of nonsense out the other end. –
Eileen I have made a function that deletes invalid UTF-8 characters from a string. I'm using it to clear description of 27000 products before it generates the XML export file.
public function stripInvalidXml($value) {
$ret = "";
$current;
if (empty($value)) {
return $ret;
}
$length = strlen($value);
for ($i=0; $i < $length; $i++) {
$current = ord($value{$i});
if (($current == 0x9) || ($current == 0xA) || ($current == 0xD) || (($current >= 0x20) && ($current <= 0xD7FF)) || (($current >= 0xE000) && ($current <= 0xFFFD)) || (($current >= 0x10000) && ($current <= 0x10FFFF))) {
$ret .= chr($current);
}
else {
$ret .= "";
}
}
return $ret;
}
ord() returns results in the range 0-255. The giant if in this function tests for unicode ranges that ord() will never return. If anybody wants to clarify why this function works the way it does I'd appreciate the insight. –
Balance $string = preg_replace('~&([a-z]{1,2})(acute|cedil|circ|grave|lig|orn|ring|slash|th|tilde|uml);~i', '$1', htmlentities($string, ENT_COMPAT, 'UTF-8'));
substr() can break your multi-byte characters!
In my case, I was using substr($string, 0, 255) to ensure a user supplied value would fit in the database. On occasion it would split a multi-byte character in half and caused database errors with "Incorrect string value".
You could use mb_substr($string,0,255), and it might be ok for MySQL 5, but MySQL 4 counts bytes instead of characters, so it would still be too long depending on the number of multi-byte characters.
To prevent these issues I implemented the following steps:
mb_substring in case it was still too longSo the rules are that the first UTF-8 octlet has the high bit set as a marker, and then 1 to 4 bits to indicate how many additional octlets; then each of the additional octlets must have the high two bits set to 10.
The pseudo-python would be:
newstring = ''
cont = 0
for each ch in string:
if cont:
if (ch >> 6) != 2: # high 2 bits are 10
# do whatever, e.g. skip it, or skip whole point, or?
else:
# acceptable continuation of multi-octlet char
newstring += ch
cont -= 1
else:
if (ch >> 7): # high bit set?
c = (ch << 1) # strip the high bit marker
while (c & 1): # while the high bit indicates another octlet
c <<= 1
cont += 1
if cont > 4:
# more than 4 octels not allowed; cope with error
if !cont:
# illegal, do something sensible
newstring += ch # or whatever
if cont:
# last utf-8 was not terminated, cope
This same logic should be translatable to php. However, its not clear what kind of stripping is to be done once you get a malformed character.
c = (ch << 1) will make (c & 1) zero the first time, skipping the loop. The test should probably be (c & 128) –
Ordeal From recent patch to Drupal's Feeds JSON parser module:
//remove everything except valid letters (from any language)
$raw = preg_replace('/(?:\\\\u[\pL\p{Zs}])+/', '', $raw);
If you're concerned yes it retains spaces as valid characters.
Did what I needed. It removes widespread nowadays emoji-characters that don't fit into MySQL's 'utf8' character set and that gave me errors like "SQLSTATE[HY000]: General error: 1366 Incorrect string value".
For details see https://www.drupal.org/node/1824506#comment-6881382
iconv is far better than the old fashioned regexp based preg_replace, wich is deprecated nowadays. –
Cetane ereg_replace(), sorry. –
Cetane \u? I don't work s lot with emojis, so maybe you know more than me. Please set up a working demo to prove how and what your preg call does. –
Nelan The next sanitizing works for me:
$string = mb_convert_encoding($string, 'UTF-8', 'UTF-8');
$string = iconv("UTF-8", "UTF-8//IGNORE", $string);
To remove all Unicode characters outside of the Unicode basic language plane:
$str = preg_replace("/[^\\x00-\\xFFFF]/", "", $str);
Slightly different to the question, but what I am doing is to use HtmlEncode(string),
pseudo code here
var encoded = HtmlEncode(string);
encoded = Regex.Replace(encoded, "&#\d+?;", "");
var result = HtmlDecode(encoded);
input and output
"Headlight\x007E Bracket, { Cafe Racer<> Style, Stainless Steel 中文呢?"
"Headlight~ Bracket, { Cafe Racer<> Style, Stainless Steel 中文呢?"
I know it's not perfect, but does the job for me.
static $preg = <<<'END'
%(
[\x09\x0A\x0D\x20-\x7E]
| [\xC2-\xDF][\x80-\xBF]
| \xE0[\xA0-\xBF][\x80-\xBF]
| [\xE1-\xEC\xEE\xEF][\x80-\xBF]{2}
| \xED[\x80-\x9F][\x80-\xBF]
| \xF0[\x90-\xBF][\x80-\xBF]{2}
| [\xF1-\xF3][\x80-\xBF]{3}
| \xF4[\x80-\x8F][\x80-\xBF]{2}
)%xs
END;
if (preg_match_all($preg, $string, $match)) {
$string = implode('', $match[0]);
} else {
$string = '';
}
it work on our service
I tried many of the solutions presented on this topic, but non of them worked for me, in my specific case. But I found a good solution on this link: https://www.ryadel.com/en/php-skip-invalid-characters-utf-8-xml-file-string/
Basically, this is the function that solved for me:
function sanitizeXML($string)
{
if (!empty($string))
{
// remove EOT+NOREP+EOX|EOT+<char> sequence (FatturaPA)
$string = preg_replace('/(\x{0004}(?:\x{201A}|\x{FFFD})(?:\x{0003}|\x{0004}).)/u', '', $string);
$regex = '/(
[\xC0-\xC1] # Invalid UTF-8 Bytes
| [\xF5-\xFF] # Invalid UTF-8 Bytes
| \xE0[\x80-\x9F] # Overlong encoding of prior code point
| \xF0[\x80-\x8F] # Overlong encoding of prior code point
| [\xC2-\xDF](?![\x80-\xBF]) # Invalid UTF-8 Sequence Start
| [\xE0-\xEF](?![\x80-\xBF]{2}) # Invalid UTF-8 Sequence Start
| [\xF0-\xF4](?![\x80-\xBF]{3}) # Invalid UTF-8 Sequence Start
| (?<=[\x0-\x7F\xF5-\xFF])[\x80-\xBF] # Invalid UTF-8 Sequence Middle
| (?<![\xC2-\xDF]|[\xE0-\xEF]|[\xE0-\xEF][\x80-\xBF]|[\xF0-\xF4]|[\xF0-\xF4][\x80-\xBF]|[\xF0-\xF4][\x80-\xBF]{2})[\x80-\xBF] # Overlong Sequence
| (?<=[\xE0-\xEF])[\x80-\xBF](?![\x80-\xBF]) # Short 3 byte sequence
| (?<=[\xF0-\xF4])[\x80-\xBF](?![\x80-\xBF]{2}) # Short 4 byte sequence
| (?<=[\xF0-\xF4][\x80-\xBF])[\x80-\xBF](?![\x80-\xBF]) # Short 4 byte sequence (2)
)/x';
$string = preg_replace($regex, '', $string);
$result = "";
$current;
$length = strlen($string);
for ($i=0; $i < $length; $i++)
{
$current = ord($string{$i});
if (($current == 0x9) ||
($current == 0xA) ||
($current == 0xD) ||
(($current >= 0x20) && ($current <= 0xD7FF)) ||
(($current >= 0xE000) && ($current <= 0xFFFD)) ||
(($current >= 0x10000) && ($current <= 0x10FFFF)))
{
$result .= chr($current);
}
else
{
$ret; // use this to strip invalid character(s)
// $ret .= " "; // use this to replace them with spaces
}
}
$string = $result;
}
return $string;
}
Hope it will help some of you.
None of the UTF functions or replacement methods above worked for me. The only thing that worked was to just explicitly allow the characters I did want to allow. This might have been because the issue was not specifically a UTF-8 issue even though that is what json_last_error_msg() told me.
$text = preg_replace('/[^0-9a-zA-Z\.\-\,\/\ ]/m', '', $text);
Removing non-utf8 characters from string:
Using ICONV:
$text = iconv("UTF-8", "UTF-8//IGNORE", $text);
Using MBSTRING:
mb_substitute_character("none");
$text = mb_convert_encoding($text, "UTF-8", "UTF-8");
Using PCRE:
$text = preg_replace("/([\x{00}-\x{7E}]|[\x{C2}-\x{DF}][\x{80}-\x{BF}]|\x{E0}[\x{A0}-\x{BF}][\x{80}-\x{BF}]|[\x{E1}-\x{EC}\x{EE}\{xEF}][\x{80}-\x{BF}]{2}|\x{ED}[\x{80}-\x{9F}][\x{80}-\x{BF}]|\x{F0}[\x{90}-\x{BF}][\x{80}-\x{BF}]{2}|[\x{F1}-\x{F3}][\x{80}-\x{BF}]{3}|\x{F4}[\x{80}-\x{8F}][\x{80}-\x{BF}]{2})|(.)/s", "$1", $text);
Please note: 0x09, 0x0A, 0x0D etc... are valid UTF-8 code-points. If you need to remove non-printable characters - this is another question.
Maybe not the most precise solution, but it gets the job done with a single line of code:
echo str_replace("?","",(utf8_decode($str)));
utf8_decode will convert the characters to a question mark;
str_replace will strip out the question marks.
$str = 'Hello?'? –
Bollay How about iconv:
http://php.net/manual/en/function.iconv.php
Haven't used it inside PHP itself but its always performed well for me on the command line. You can get it to substitute invalid characters.
© 2022 - 2024 — McMap. All rights reserved.
$string = mb_convert_encoding($string, 'UTF-8', 'UTF-8');from https://mcmap.net/q/145636/-replacing-invalid-utf-8-characters-by-question-marks-mbstring-substitute_character-seems-ignored/1066234 (leaves "?" symbol for non-UTF8 characters). – Roberge