I have a dataframe with an id column and a quantity column, which can be 0 or 1.
import pandas as pd
df = pd.DataFrame([
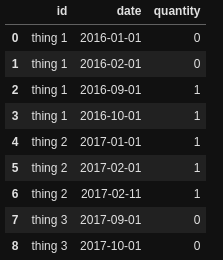
{'id': 'thing 1', 'date': '2016-01-01', 'quantity': 0 },
{'id': 'thing 1', 'date': '2016-02-01', 'quantity': 0 },
{'id': 'thing 1', 'date': '2016-09-01', 'quantity': 1 },
{'id': 'thing 1', 'date': '2016-10-01', 'quantity': 1 },
{'id': 'thing 2', 'date': '2017-01-01', 'quantity': 1 },
{'id': 'thing 2', 'date': '2017-02-01', 'quantity': 1 },
{'id': 'thing 2', 'date': '2017-02-11', 'quantity': 1 },
{'id': 'thing 3', 'date': '2017-09-01', 'quantity': 0 },
{'id': 'thing 3', 'date': '2017-10-01', 'quantity': 0 },
])
df.date = pd.to_datetime(df.date, format="%Y-%m-%d")
df
If for a certain id I have both 0 and 1 values, I want to return only the 1s. If I have only 1s, I want to return all of them. If I have only 0s, I want to return all of them.
The way I do it is to apply a function to each group and then reset the index:
def drop_that(dff):
q = len(dff[dff['quantity']==1])
if q >0:
return dff[dff['quantity']==1]
else:
return dff
dfg = df.groupby('id', as_index=False).apply(drop_that)
dfg.reset_index(drop=True)

However, I implemented this just by brute-force googling and I really do not know if this is a good Pandas practice or if there are alternative methods that would be more performant.
Any advice would really be appreciated.